diff --git a/main.py b/main.py
index 5bc0656..42d0f29 100644
--- a/main.py
+++ b/main.py
@@ -48,7 +48,7 @@ def main():
videoGameWindow = videoGameWindows[0]
except:
print("The game window you are trying to select doesn't exist.")
- print("Check variable videoGameWindowTitle (typically on line 13")
+ print("Check variable videoGameWindowTitle (typically on line 17)")
exit()
# Select that Window
@@ -222,6 +222,8 @@ if __name__ == "__main__":
try:
main()
except Exception as e:
+ import traceback
print("Please read the below message and think about how it could be solved before posting it on discord.")
+ traceback.print_exception(e)
print(str(e))
print("Please read the above message and think about how it could be solved before posting it on discord.")
diff --git a/main_onnx_cpu.py b/main_onnx_cpu.py
index 73dedf6..3420a34 100644
--- a/main_onnx_cpu.py
+++ b/main_onnx_cpu.py
@@ -209,6 +209,8 @@ if __name__ == "__main__":
try:
main()
except Exception as e:
+ import traceback
print("Please read the below message and think about how it could be solved before posting it on discord.")
+ traceback.print_exception(e)
print(str(e))
- print("Please read the above message and think about how it could be solved before posting it on discord.")
\ No newline at end of file
+ print("Please read the above message and think about how it could be solved before posting it on discord.")
diff --git a/main_onnx_gpu.py b/main_onnx_gpu.py
index 527a9be..13aca23 100644
--- a/main_onnx_gpu.py
+++ b/main_onnx_gpu.py
@@ -207,6 +207,8 @@ if __name__ == "__main__":
try:
main()
except Exception as e:
+ import traceback
print("Please read the below message and think about how it could be solved before posting it on discord.")
+ traceback.print_exception(e)
print(str(e))
- print("Please read the above message and think about how it could be solved before posting it on discord.")
\ No newline at end of file
+ print("Please read the above message and think about how it could be solved before posting it on discord.")
diff --git a/main_tensorrt_gpu.py b/main_tensorrt_gpu.py
index c931c25..d6e8b71 100644
--- a/main_tensorrt_gpu.py
+++ b/main_tensorrt_gpu.py
@@ -94,7 +94,7 @@ def main():
sTime = time.time()
# Loading Yolo5 Small AI Model
- model = DetectMultiBackend('yolov5s320Half.engine', device=torch.device(
+ model = DetectMultiBackend('yolov5s.engine', device=torch.device(
'cuda'), dnn=False, data='', fp16=True)
stride, names, pt = model.stride, model.names, model.pt
@@ -215,6 +215,8 @@ if __name__ == "__main__":
try:
main()
except Exception as e:
+ import traceback
print("Please read the below message and think about how it could be solved before posting it on discord.")
+ traceback.print_exception(e)
print(str(e))
- print("Please read the above message and think about how it could be solved before posting it on discord.")
\ No newline at end of file
+ print("Please read the above message and think about how it could be solved before posting it on discord.")
diff --git a/main_torch_gpu.py b/main_torch_gpu.py
index 5fff29b..f654aac 100644
--- a/main_torch_gpu.py
+++ b/main_torch_gpu.py
@@ -216,6 +216,8 @@ if __name__ == "__main__":
try:
main()
except Exception as e:
+ import traceback
print("Please read the below message and think about how it could be solved before posting it on discord.")
+ traceback.print_exception(e)
print(str(e))
- print("Please read the above message and think about how it could be solved before posting it on discord.")
\ No newline at end of file
+ print("Please read the above message and think about how it could be solved before posting it on discord.")
diff --git a/models/__pycache__/__init__.cpython-310.pyc b/models/__pycache__/__init__.cpython-310.pyc
deleted file mode 100644
index 7cb496d..0000000
Binary files a/models/__pycache__/__init__.cpython-310.pyc and /dev/null differ
diff --git a/models/__pycache__/__init__.cpython-39.pyc b/models/__pycache__/__init__.cpython-39.pyc
deleted file mode 100644
index 230c9e6..0000000
Binary files a/models/__pycache__/__init__.cpython-39.pyc and /dev/null differ
diff --git a/models/__pycache__/common.cpython-310.pyc b/models/__pycache__/common.cpython-310.pyc
deleted file mode 100644
index 95d2011..0000000
Binary files a/models/__pycache__/common.cpython-310.pyc and /dev/null differ
diff --git a/models/__pycache__/common.cpython-39.pyc b/models/__pycache__/common.cpython-39.pyc
deleted file mode 100644
index 3cf3602..0000000
Binary files a/models/__pycache__/common.cpython-39.pyc and /dev/null differ
diff --git a/models/__pycache__/experimental.cpython-310.pyc b/models/__pycache__/experimental.cpython-310.pyc
deleted file mode 100644
index 72783d9..0000000
Binary files a/models/__pycache__/experimental.cpython-310.pyc and /dev/null differ
diff --git a/models/__pycache__/experimental.cpython-39.pyc b/models/__pycache__/experimental.cpython-39.pyc
deleted file mode 100644
index 9512f09..0000000
Binary files a/models/__pycache__/experimental.cpython-39.pyc and /dev/null differ
diff --git a/models/__pycache__/yolo.cpython-310.pyc b/models/__pycache__/yolo.cpython-310.pyc
deleted file mode 100644
index 1a94ae2..0000000
Binary files a/models/__pycache__/yolo.cpython-310.pyc and /dev/null differ
diff --git a/models/__pycache__/yolo.cpython-39.pyc b/models/__pycache__/yolo.cpython-39.pyc
deleted file mode 100644
index f4acc44..0000000
Binary files a/models/__pycache__/yolo.cpython-39.pyc and /dev/null differ
diff --git a/models/common.py b/models/common.py
index 833ece2..10bbd8a 100644
--- a/models/common.py
+++ b/models/common.py
@@ -3,10 +3,13 @@
Common modules
"""
+import ast
+import contextlib
import json
import math
import platform
import warnings
+import zipfile
from collections import OrderedDict, namedtuple
from copy import copy
from pathlib import Path
@@ -18,35 +21,19 @@ import pandas as pd
import requests
import torch
import torch.nn as nn
+from IPython.display import display
from PIL import Image
from torch.cuda import amp
+from utils import TryExcept
from utils.dataloaders import exif_transpose, letterbox
from utils.general import (LOGGER, ROOT, Profile, check_requirements, check_suffix, check_version, colorstr,
- increment_path, make_divisible, non_max_suppression, scale_boxes, xywh2xyxy, xyxy2xywh,
- yaml_load)
+ increment_path, is_notebook, make_divisible, non_max_suppression, scale_boxes, xywh2xyxy,
+ xyxy2xywh, yaml_load)
from utils.plots import Annotator, colors, save_one_box
from utils.torch_utils import copy_attr, smart_inference_mode
-def export_formats():
- # YOLOv5 export formats
- x = [
- ['PyTorch', '-', '.pt', True, True],
- ['TorchScript', 'torchscript', '.torchscript', True, True],
- ['ONNX', 'onnx', '.onnx', True, True],
- ['OpenVINO', 'openvino', '_openvino_model', True, False],
- ['TensorRT', 'engine', '.engine', False, True],
- ['CoreML', 'coreml', '.mlmodel', True, False],
- ['TensorFlow SavedModel', 'saved_model', '_saved_model', True, True],
- ['TensorFlow GraphDef', 'pb', '.pb', True, True],
- ['TensorFlow Lite', 'tflite', '.tflite', True, False],
- ['TensorFlow Edge TPU', 'edgetpu', '_edgetpu.tflite', False, False],
- ['TensorFlow.js', 'tfjs', '_web_model', False, False],
- ['PaddlePaddle', 'paddle', '_paddle_model', True, True], ]
- return pd.DataFrame(x, columns=['Format', 'Argument', 'Suffix', 'CPU', 'GPU'])
-
-
def autopad(k, p=None, d=1): # kernel, padding, dilation
# Pad to 'same' shape outputs
if d > 1:
@@ -351,7 +338,7 @@ class DetectMultiBackend(nn.Module):
# TorchScript: *.torchscript
# ONNX Runtime: *.onnx
# ONNX OpenCV DNN: *.onnx --dnn
- # OpenVINO: *.xml
+ # OpenVINO: *_openvino_model
# CoreML: *.mlmodel
# TensorRT: *.engine
# TensorFlow SavedModel: *_saved_model
@@ -519,6 +506,13 @@ class DetectMultiBackend(nn.Module):
interpreter.allocate_tensors() # allocate
input_details = interpreter.get_input_details() # inputs
output_details = interpreter.get_output_details() # outputs
+ # load metadata
+ with contextlib.suppress(zipfile.BadZipFile):
+ with zipfile.ZipFile(w, "r") as model:
+ meta_file = model.namelist()[0]
+ meta = ast.literal_eval(
+ model.read(meta_file).decode("utf-8"))
+ stride, names = int(meta['stride']), meta['names']
elif tfjs: # TF.js
raise NotImplementedError(
'ERROR: YOLOv5 TF.js inference is not supported')
@@ -527,7 +521,7 @@ class DetectMultiBackend(nn.Module):
check_requirements('paddlepaddle-gpu' if cuda else 'paddlepaddle')
import paddle.inference as pdi
if not Path(w).is_file(): # if not *.pdmodel
- # get *.xml file from *_openvino_model dir
+ # get *.pdmodel file from *_paddle_model dir
w = next(Path(w).rglob('*.pdmodel'))
weights = Path(w).with_suffix('.pdiparams')
config = pdi.Config(str(w), str(weights))
@@ -671,7 +665,8 @@ class DetectMultiBackend(nn.Module):
# Return model type from model path, i.e. path='path/to/model.onnx' -> type=onnx
# types = [pt, jit, onnx, xml, engine, coreml, saved_model, pb, tflite, edgetpu, tfjs, paddle]
from utils.downloads import is_url
- sf = list(export_formats().Suffix) # export suffixes
+ sf = ['.pt', '.torchscript', '.onnx', '_openvino_model', '.engine', '.mlmodel', '_saved_model',
+ '.pb', '.tflite', '_edgetpu.tflite', '_web_model', '_paddle_model'] # export suffixes
if not is_url(p, check=False):
check_suffix(p, sf) # checks
url = urlparse(p) # if url may be Triton inference server
@@ -775,11 +770,11 @@ class AutoShape(nn.Module):
s = im.shape[:2] # HWC
shape0.append(s) # image shape
g = max(size) / max(s) # gain
- shape1.append([y * g for y in s])
+ shape1.append([int(y * g) for y in s])
ims[i] = im if im.data.contiguous else np.ascontiguousarray(
im) # update
- shape1 = [make_divisible(x, self.stride) for x in np.array(
- shape1).max(0)] if self.pt else size # inf shape
+ shape1 = [make_divisible(x, self.stride)
+ for x in np.array(shape1).max(0)] # inf shape
x = [letterbox(im, shape1, auto=False)[0] for im in ims] # pad
x = np.ascontiguousarray(np.array(x).transpose(
(0, 3, 1, 2))) # stack and BHWC to BCHW
@@ -862,7 +857,7 @@ class Detections:
im = Image.fromarray(im.astype(np.uint8)) if isinstance(
im, np.ndarray) else im # from np
if show:
- im.show(self.files[i]) # show
+ display(im) if is_notebook() else im.show(self.files[i])
if save:
f = self.files[i]
im.save(save_dir / f) # save
@@ -879,17 +874,18 @@ class Detections:
LOGGER.info(f'Saved results to {save_dir}\n')
return crops
+ @TryExcept('Showing images is not supported in this environment')
def show(self, labels=True):
self._run(show=True, labels=labels) # show results
- def save(self, labels=True, save_dir='runs/detect/exp'):
+ def save(self, labels=True, save_dir='runs/detect/exp', exist_ok=False):
save_dir = increment_path(
- save_dir, exist_ok=save_dir != 'runs/detect/exp', mkdir=True) # increment save_dir
+ save_dir, exist_ok, mkdir=True) # increment save_dir
self._run(save=True, labels=labels, save_dir=save_dir) # save results
- def crop(self, save=True, save_dir='runs/detect/exp'):
+ def crop(self, save=True, save_dir='runs/detect/exp', exist_ok=False):
save_dir = increment_path(
- save_dir, exist_ok=save_dir != 'runs/detect/exp', mkdir=True) if save else None
+ save_dir, exist_ok, mkdir=True) if save else None
# crop results
return self._run(crop=True, save=save, save_dir=save_dir)
diff --git a/models/tf.py b/models/tf.py
index 1446d88..3f3dc8d 100644
--- a/models/tf.py
+++ b/models/tf.py
@@ -333,6 +333,7 @@ class TFSegment(TFDetect):
def call(self, x):
p = self.proto(x[0])
+ # p = TFUpsample(None, scale_factor=4, mode='nearest')(self.proto(x[0])) # (optional) full-size protos
p = tf.transpose(p, [0, 3, 1, 2]) # from shape(1,160,160,32) to shape(1,32,160,160)
x = self.detect(self, x)
return (x, p) if self.training else (x[0], p)
@@ -355,8 +356,8 @@ class TFUpsample(keras.layers.Layer):
# TF version of torch.nn.Upsample()
def __init__(self, size, scale_factor, mode, w=None): # warning: all arguments needed including 'w'
super().__init__()
- assert scale_factor == 2, "scale_factor must be 2"
- self.upsample = lambda x: tf.image.resize(x, (x.shape[1] * 2, x.shape[2] * 2), method=mode)
+ assert scale_factor % 2 == 0, "scale_factor must be multiple of 2"
+ self.upsample = lambda x: tf.image.resize(x, (x.shape[1] * scale_factor, x.shape[2] * scale_factor), mode)
# self.upsample = keras.layers.UpSampling2D(size=scale_factor, interpolation=mode)
# with default arguments: align_corners=False, half_pixel_centers=False
# self.upsample = lambda x: tf.raw_ops.ResizeNearestNeighbor(images=x,
diff --git a/requirements.txt b/requirements.txt
index d7ff83b..4be4bff 100644
--- a/requirements.txt
+++ b/requirements.txt
@@ -11,3 +11,5 @@ tqdm
matplotlib
seaborn
requests
+ipython
+psutil
\ No newline at end of file
diff --git a/utils/__init__.py b/utils/__init__.py
index 24746d2..3b1a2c8 100644
--- a/utils/__init__.py
+++ b/utils/__init__.py
@@ -23,7 +23,7 @@ class TryExcept(contextlib.ContextDecorator):
def __exit__(self, exc_type, value, traceback):
if value:
- print(emojis(f'{self.msg}{value}'))
+ print(emojis(f"{self.msg}{': ' if self.msg else ''}{value}"))
return True
@@ -37,6 +37,16 @@ def threaded(func):
return wrapper
+def join_threads(verbose=False):
+ # Join all daemon threads, i.e. atexit.register(lambda: join_threads())
+ main_thread = threading.current_thread()
+ for t in threading.enumerate():
+ if t is not main_thread:
+ if verbose:
+ print(f'Joining thread {t.name}')
+ t.join()
+
+
def notebook_init(verbose=True):
# Check system software and hardware
print('Checking setup...')
@@ -47,7 +57,6 @@ def notebook_init(verbose=True):
from utils.general import check_font, check_requirements, is_colab
from utils.torch_utils import select_device # imports
- check_requirements(('psutil', 'IPython'))
check_font()
import psutil
diff --git a/utils/__pycache__/__init__.cpython-310.pyc b/utils/__pycache__/__init__.cpython-310.pyc
deleted file mode 100644
index ba6c3d5..0000000
Binary files a/utils/__pycache__/__init__.cpython-310.pyc and /dev/null differ
diff --git a/utils/__pycache__/__init__.cpython-39.pyc b/utils/__pycache__/__init__.cpython-39.pyc
deleted file mode 100644
index ec5d71f..0000000
Binary files a/utils/__pycache__/__init__.cpython-39.pyc and /dev/null differ
diff --git a/utils/__pycache__/augmentations.cpython-310.pyc b/utils/__pycache__/augmentations.cpython-310.pyc
deleted file mode 100644
index eb6e497..0000000
Binary files a/utils/__pycache__/augmentations.cpython-310.pyc and /dev/null differ
diff --git a/utils/__pycache__/augmentations.cpython-39.pyc b/utils/__pycache__/augmentations.cpython-39.pyc
deleted file mode 100644
index 8ebec04..0000000
Binary files a/utils/__pycache__/augmentations.cpython-39.pyc and /dev/null differ
diff --git a/utils/__pycache__/autoanchor.cpython-310.pyc b/utils/__pycache__/autoanchor.cpython-310.pyc
deleted file mode 100644
index d606b9e..0000000
Binary files a/utils/__pycache__/autoanchor.cpython-310.pyc and /dev/null differ
diff --git a/utils/__pycache__/autoanchor.cpython-39.pyc b/utils/__pycache__/autoanchor.cpython-39.pyc
deleted file mode 100644
index 4c1a947..0000000
Binary files a/utils/__pycache__/autoanchor.cpython-39.pyc and /dev/null differ
diff --git a/utils/__pycache__/dataloaders.cpython-310.pyc b/utils/__pycache__/dataloaders.cpython-310.pyc
deleted file mode 100644
index 9285b99..0000000
Binary files a/utils/__pycache__/dataloaders.cpython-310.pyc and /dev/null differ
diff --git a/utils/__pycache__/dataloaders.cpython-39.pyc b/utils/__pycache__/dataloaders.cpython-39.pyc
deleted file mode 100644
index bb28764..0000000
Binary files a/utils/__pycache__/dataloaders.cpython-39.pyc and /dev/null differ
diff --git a/utils/__pycache__/downloads.cpython-310.pyc b/utils/__pycache__/downloads.cpython-310.pyc
deleted file mode 100644
index ce5ff93..0000000
Binary files a/utils/__pycache__/downloads.cpython-310.pyc and /dev/null differ
diff --git a/utils/__pycache__/downloads.cpython-39.pyc b/utils/__pycache__/downloads.cpython-39.pyc
deleted file mode 100644
index 699f0ad..0000000
Binary files a/utils/__pycache__/downloads.cpython-39.pyc and /dev/null differ
diff --git a/utils/__pycache__/general.cpython-310.pyc b/utils/__pycache__/general.cpython-310.pyc
deleted file mode 100644
index 010e088..0000000
Binary files a/utils/__pycache__/general.cpython-310.pyc and /dev/null differ
diff --git a/utils/__pycache__/general.cpython-39.pyc b/utils/__pycache__/general.cpython-39.pyc
deleted file mode 100644
index f096d60..0000000
Binary files a/utils/__pycache__/general.cpython-39.pyc and /dev/null differ
diff --git a/utils/__pycache__/metrics.cpython-310.pyc b/utils/__pycache__/metrics.cpython-310.pyc
deleted file mode 100644
index c24832e..0000000
Binary files a/utils/__pycache__/metrics.cpython-310.pyc and /dev/null differ
diff --git a/utils/__pycache__/metrics.cpython-39.pyc b/utils/__pycache__/metrics.cpython-39.pyc
deleted file mode 100644
index 9d80778..0000000
Binary files a/utils/__pycache__/metrics.cpython-39.pyc and /dev/null differ
diff --git a/utils/__pycache__/plots.cpython-310.pyc b/utils/__pycache__/plots.cpython-310.pyc
deleted file mode 100644
index b7b7670..0000000
Binary files a/utils/__pycache__/plots.cpython-310.pyc and /dev/null differ
diff --git a/utils/__pycache__/plots.cpython-39.pyc b/utils/__pycache__/plots.cpython-39.pyc
deleted file mode 100644
index 77cf6c1..0000000
Binary files a/utils/__pycache__/plots.cpython-39.pyc and /dev/null differ
diff --git a/utils/__pycache__/torch_utils.cpython-310.pyc b/utils/__pycache__/torch_utils.cpython-310.pyc
deleted file mode 100644
index c9e1ca1..0000000
Binary files a/utils/__pycache__/torch_utils.cpython-310.pyc and /dev/null differ
diff --git a/utils/__pycache__/torch_utils.cpython-39.pyc b/utils/__pycache__/torch_utils.cpython-39.pyc
deleted file mode 100644
index 3239699..0000000
Binary files a/utils/__pycache__/torch_utils.cpython-39.pyc and /dev/null differ
diff --git a/utils/augmentations.py b/utils/augmentations.py
index 7c8e0bc..1eae5db 100644
--- a/utils/augmentations.py
+++ b/utils/augmentations.py
@@ -250,12 +250,10 @@ def copy_paste(im, labels, segments, p=0.5):
if (ioa < 0.30).all(): # allow 30% obscuration of existing labels
labels = np.concatenate((labels, [[l[0], *box]]), 0)
segments.append(np.concatenate((w - s[:, 0:1], s[:, 1:2]), 1))
- cv2.drawContours(im_new, [segments[j].astype(np.int32)], -1, (255, 255, 255), cv2.FILLED)
+ cv2.drawContours(im_new, [segments[j].astype(np.int32)], -1, (1, 1, 1), cv2.FILLED)
- result = cv2.bitwise_and(src1=im, src2=im_new)
- result = cv2.flip(result, 1) # augment segments (flip left-right)
- i = result > 0 # pixels to replace
- # i[:, :] = result.max(2).reshape(h, w, 1) # act over ch
+ result = cv2.flip(im, 1) # augment segments (flip left-right)
+ i = cv2.flip(im_new, 1).astype(bool)
im[i] = result[i] # cv2.imwrite('debug.jpg', im) # debug
return im, labels, segments
diff --git a/utils/autoanchor.py b/utils/autoanchor.py
index 7e7e998..bb5cf6e 100644
--- a/utils/autoanchor.py
+++ b/utils/autoanchor.py
@@ -11,7 +11,7 @@ import yaml
from tqdm import tqdm
from utils import TryExcept
-from utils.general import LOGGER, colorstr
+from utils.general import LOGGER, TQDM_BAR_FORMAT, colorstr
PREFIX = colorstr('AutoAnchor: ')
@@ -26,7 +26,7 @@ def check_anchor_order(m):
m.anchors[:] = m.anchors.flip(0)
-@TryExcept(f'{PREFIX}ERROR: ')
+@TryExcept(f'{PREFIX}ERROR')
def check_anchors(dataset, model, thr=4.0, imgsz=640):
# Check anchor fit to data, recompute if necessary
m = model.module.model[-1] if hasattr(model, 'module') else model.model[-1] # Detect()
@@ -153,7 +153,7 @@ def kmean_anchors(dataset='./data/coco128.yaml', n=9, img_size=640, thr=4.0, gen
# Evolve
f, sh, mp, s = anchor_fitness(k), k.shape, 0.9, 0.1 # fitness, generations, mutation prob, sigma
- pbar = tqdm(range(gen), bar_format='{l_bar}{bar:10}{r_bar}{bar:-10b}') # progress bar
+ pbar = tqdm(range(gen), bar_format=TQDM_BAR_FORMAT) # progress bar
for _ in pbar:
v = np.ones(sh)
while (v == 1).all(): # mutate until a change occurs (prevent duplicates)
diff --git a/utils/benchmarks.py b/utils/benchmarks.py
deleted file mode 100644
index d5f4c1d..0000000
--- a/utils/benchmarks.py
+++ /dev/null
@@ -1,161 +0,0 @@
-# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
-"""
-Run YOLOv5 benchmarks on all supported export formats
-
-Format | `export.py --include` | Model
---- | --- | ---
-PyTorch | - | yolov5s.pt
-TorchScript | `torchscript` | yolov5s.torchscript
-ONNX | `onnx` | yolov5s.onnx
-OpenVINO | `openvino` | yolov5s_openvino_model/
-TensorRT | `engine` | yolov5s.engine
-CoreML | `coreml` | yolov5s.mlmodel
-TensorFlow SavedModel | `saved_model` | yolov5s_saved_model/
-TensorFlow GraphDef | `pb` | yolov5s.pb
-TensorFlow Lite | `tflite` | yolov5s.tflite
-TensorFlow Edge TPU | `edgetpu` | yolov5s_edgetpu.tflite
-TensorFlow.js | `tfjs` | yolov5s_web_model/
-
-Requirements:
- $ pip install -r requirements.txt coremltools onnx onnx-simplifier onnxruntime openvino-dev tensorflow-cpu # CPU
- $ pip install -r requirements.txt coremltools onnx onnx-simplifier onnxruntime-gpu openvino-dev tensorflow # GPU
- $ pip install -U nvidia-tensorrt --index-url https://pypi.ngc.nvidia.com # TensorRT
-
-Usage:
- $ python utils/benchmarks.py --weights yolov5s.pt --img 640
-"""
-
-import argparse
-import platform
-import sys
-import time
-from pathlib import Path
-
-import pandas as pd
-
-FILE = Path(__file__).resolve()
-ROOT = FILE.parents[1] # YOLOv5 root directory
-if str(ROOT) not in sys.path:
- sys.path.append(str(ROOT)) # add ROOT to PATH
-# ROOT = ROOT.relative_to(Path.cwd()) # relative
-
-import export
-import val
-from utils import notebook_init
-from utils.general import LOGGER, check_yaml, file_size, print_args
-from utils.torch_utils import select_device
-
-
-def run(
- weights=ROOT / 'yolov5s.pt', # weights path
- imgsz=640, # inference size (pixels)
- batch_size=1, # batch size
- data=ROOT / 'data/coco128.yaml', # dataset.yaml path
- device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
- half=False, # use FP16 half-precision inference
- test=False, # test exports only
- pt_only=False, # test PyTorch only
- hard_fail=False, # throw error on benchmark failure
-):
- y, t = [], time.time()
- device = select_device(device)
- for i, (name, f, suffix, cpu, gpu) in export.export_formats().iterrows(): # index, (name, file, suffix, CPU, GPU)
- try:
- assert i not in (9, 10), 'inference not supported' # Edge TPU and TF.js are unsupported
- assert i != 5 or platform.system() == 'Darwin', 'inference only supported on macOS>=10.13' # CoreML
- if 'cpu' in device.type:
- assert cpu, 'inference not supported on CPU'
- if 'cuda' in device.type:
- assert gpu, 'inference not supported on GPU'
-
- # Export
- if f == '-':
- w = weights # PyTorch format
- else:
- w = export.run(weights=weights, imgsz=[imgsz], include=[f], device=device, half=half)[-1] # all others
- assert suffix in str(w), 'export failed'
-
- # Validate
- result = val.run(data, w, batch_size, imgsz, plots=False, device=device, task='benchmark', half=half)
- metrics = result[0] # metrics (mp, mr, map50, map, *losses(box, obj, cls))
- speeds = result[2] # times (preprocess, inference, postprocess)
- y.append([name, round(file_size(w), 1), round(metrics[3], 4), round(speeds[1], 2)]) # MB, mAP, t_inference
- except Exception as e:
- if hard_fail:
- assert type(e) is AssertionError, f'Benchmark --hard-fail for {name}: {e}'
- LOGGER.warning(f'WARNING: Benchmark failure for {name}: {e}')
- y.append([name, None, None, None]) # mAP, t_inference
- if pt_only and i == 0:
- break # break after PyTorch
-
- # Print results
- LOGGER.info('\n')
- parse_opt()
- notebook_init() # print system info
- c = ['Format', 'Size (MB)', 'mAP50-95', 'Inference time (ms)'] if map else ['Format', 'Export', '', '']
- py = pd.DataFrame(y, columns=c)
- LOGGER.info(f'\nBenchmarks complete ({time.time() - t:.2f}s)')
- LOGGER.info(str(py if map else py.iloc[:, :2]))
- if hard_fail and isinstance(hard_fail, str):
- metrics = py['mAP50-95'].array # values to compare to floor
- floor = eval(hard_fail) # minimum metric floor to pass, i.e. = 0.29 mAP for YOLOv5n
- assert all(x > floor for x in metrics if pd.notna(x)), f'HARD FAIL: mAP50-95 < floor {floor}'
- return py
-
-
-def test(
- weights=ROOT / 'yolov5s.pt', # weights path
- imgsz=640, # inference size (pixels)
- batch_size=1, # batch size
- data=ROOT / 'data/coco128.yaml', # dataset.yaml path
- device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
- half=False, # use FP16 half-precision inference
- test=False, # test exports only
- pt_only=False, # test PyTorch only
- hard_fail=False, # throw error on benchmark failure
-):
- y, t = [], time.time()
- device = select_device(device)
- for i, (name, f, suffix, gpu) in export.export_formats().iterrows(): # index, (name, file, suffix, gpu-capable)
- try:
- w = weights if f == '-' else \
- export.run(weights=weights, imgsz=[imgsz], include=[f], device=device, half=half)[-1] # weights
- assert suffix in str(w), 'export failed'
- y.append([name, True])
- except Exception:
- y.append([name, False]) # mAP, t_inference
-
- # Print results
- LOGGER.info('\n')
- parse_opt()
- notebook_init() # print system info
- py = pd.DataFrame(y, columns=['Format', 'Export'])
- LOGGER.info(f'\nExports complete ({time.time() - t:.2f}s)')
- LOGGER.info(str(py))
- return py
-
-
-def parse_opt():
- parser = argparse.ArgumentParser()
- parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='weights path')
- parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='inference size (pixels)')
- parser.add_argument('--batch-size', type=int, default=1, help='batch size')
- parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
- parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
- parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
- parser.add_argument('--test', action='store_true', help='test exports only')
- parser.add_argument('--pt-only', action='store_true', help='test PyTorch only')
- parser.add_argument('--hard-fail', nargs='?', const=True, default=False, help='Exception on error or < min metric')
- opt = parser.parse_args()
- opt.data = check_yaml(opt.data) # check YAML
- print_args(vars(opt))
- return opt
-
-
-def main(opt):
- test(**vars(opt)) if opt.test else run(**vars(opt))
-
-
-if __name__ == "__main__":
- opt = parse_opt()
- main(opt)
diff --git a/utils/dataloaders.py b/utils/dataloaders.py
index 6cd1da6..cbb3114 100644
--- a/utils/dataloaders.py
+++ b/utils/dataloaders.py
@@ -17,9 +17,9 @@ from multiprocessing.pool import Pool, ThreadPool
from pathlib import Path
from threading import Thread
from urllib.parse import urlparse
-from zipfile import ZipFile
import numpy as np
+import psutil
import torch
import torch.nn.functional as F
import torchvision
@@ -30,15 +30,15 @@ from tqdm import tqdm
from utils.augmentations import (Albumentations, augment_hsv, classify_albumentations, classify_transforms, copy_paste,
letterbox, mixup, random_perspective)
-from utils.general import (DATASETS_DIR, LOGGER, NUM_THREADS, check_dataset, check_requirements, check_yaml, clean_str,
- cv2, is_colab, is_kaggle, segments2boxes, xyn2xy, xywh2xyxy, xywhn2xyxy, xyxy2xywhn)
+from utils.general import (DATASETS_DIR, LOGGER, NUM_THREADS, TQDM_BAR_FORMAT, check_dataset, check_requirements,
+ check_yaml, clean_str, cv2, is_colab, is_kaggle, segments2boxes, unzip_file, xyn2xy,
+ xywh2xyxy, xywhn2xyxy, xyxy2xywhn)
from utils.torch_utils import torch_distributed_zero_first
# Parameters
HELP_URL = 'See https://github.com/ultralytics/yolov5/wiki/Train-Custom-Data'
IMG_FORMATS = 'bmp', 'dng', 'jpeg', 'jpg', 'mpo', 'png', 'tif', 'tiff', 'webp', 'pfm' # include image suffixes
VID_FORMATS = 'asf', 'avi', 'gif', 'm4v', 'mkv', 'mov', 'mp4', 'mpeg', 'mpg', 'ts', 'wmv' # include video suffixes
-BAR_FORMAT = '{l_bar}{bar:10}{r_bar}{bar:-10b}' # tqdm bar format
LOCAL_RANK = int(os.getenv('LOCAL_RANK', -1)) # https://pytorch.org/docs/stable/elastic/run.html
RANK = int(os.getenv('RANK', -1))
PIN_MEMORY = str(os.getenv('PIN_MEMORY', True)).lower() == 'true' # global pin_memory for dataloaders
@@ -115,7 +115,8 @@ def create_dataloader(path,
image_weights=False,
quad=False,
prefix='',
- shuffle=False):
+ shuffle=False,
+ seed=0):
if rect and shuffle:
LOGGER.warning('WARNING ⚠️ --rect is incompatible with DataLoader shuffle, setting shuffle=False')
shuffle = False
@@ -140,7 +141,7 @@ def create_dataloader(path,
sampler = None if rank == -1 else distributed.DistributedSampler(dataset, shuffle=shuffle)
loader = DataLoader if image_weights else InfiniteDataLoader # only DataLoader allows for attribute updates
generator = torch.Generator()
- generator.manual_seed(6148914691236517205 + RANK)
+ generator.manual_seed(6148914691236517205 + seed + RANK)
return loader(dataset,
batch_size=batch_size,
shuffle=shuffle and sampler is None,
@@ -238,6 +239,8 @@ class LoadScreenshots:
class LoadImages:
# YOLOv5 image/video dataloader, i.e. `python detect.py --source image.jpg/vid.mp4`
def __init__(self, path, img_size=640, stride=32, auto=True, transforms=None, vid_stride=1):
+ if isinstance(path, str) and Path(path).suffix == ".txt": # *.txt file with img/vid/dir on each line
+ path = Path(path).read_text().rsplit()
files = []
for p in sorted(path) if isinstance(path, (list, tuple)) else [path]:
p = str(Path(p).resolve())
@@ -338,13 +341,13 @@ class LoadImages:
class LoadStreams:
# YOLOv5 streamloader, i.e. `python detect.py --source 'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP streams`
- def __init__(self, sources='streams.txt', img_size=640, stride=32, auto=True, transforms=None, vid_stride=1):
+ def __init__(self, sources='file.streams', img_size=640, stride=32, auto=True, transforms=None, vid_stride=1):
torch.backends.cudnn.benchmark = True # faster for fixed-size inference
self.mode = 'stream'
self.img_size = img_size
self.stride = stride
self.vid_stride = vid_stride # video frame-rate stride
- sources = Path(sources).read_text().rsplit() if Path(sources).is_file() else [sources]
+ sources = Path(sources).read_text().rsplit() if os.path.isfile(sources) else [sources]
n = len(sources)
self.sources = [clean_str(x) for x in sources] # clean source names for later
self.imgs, self.fps, self.frames, self.threads = [None] * n, [0] * n, [0] * n, [None] * n
@@ -352,6 +355,7 @@ class LoadStreams:
# Start thread to read frames from video stream
st = f'{i + 1}/{n}: {s}... '
if urlparse(s).hostname in ('www.youtube.com', 'youtube.com', 'youtu.be'): # if source is YouTube video
+ # YouTube format i.e. 'https://www.youtube.com/watch?v=Zgi9g1ksQHc' or 'https://youtu.be/Zgi9g1ksQHc'
check_requirements(('pafy', 'youtube_dl==2020.12.2'))
import pafy
s = pafy.new(s).getbest(preftype="mp4").url # YouTube URL
@@ -444,6 +448,7 @@ class LoadImagesAndLabels(Dataset):
single_cls=False,
stride=32,
pad=0.0,
+ min_items=0,
prefix=''):
self.img_size = img_size
self.augment = augment
@@ -467,15 +472,15 @@ class LoadImagesAndLabels(Dataset):
with open(p) as t:
t = t.read().strip().splitlines()
parent = str(p.parent) + os.sep
- f += [x.replace('./', parent) if x.startswith('./') else x for x in t] # local to global path
- # f += [p.parent / x.lstrip(os.sep) for x in t] # local to global path (pathlib)
+ f += [x.replace('./', parent, 1) if x.startswith('./') else x for x in t] # to global path
+ # f += [p.parent / x.lstrip(os.sep) for x in t] # to global path (pathlib)
else:
raise FileNotFoundError(f'{prefix}{p} does not exist')
self.im_files = sorted(x.replace('/', os.sep) for x in f if x.split('.')[-1].lower() in IMG_FORMATS)
# self.img_files = sorted([x for x in f if x.suffix[1:].lower() in IMG_FORMATS]) # pathlib
assert self.im_files, f'{prefix}No images found'
except Exception as e:
- raise Exception(f'{prefix}Error loading data from {path}: {e}\n{HELP_URL}')
+ raise Exception(f'{prefix}Error loading data from {path}: {e}\n{HELP_URL}') from e
# Check cache
self.label_files = img2label_paths(self.im_files) # labels
@@ -490,8 +495,8 @@ class LoadImagesAndLabels(Dataset):
# Display cache
nf, nm, ne, nc, n = cache.pop('results') # found, missing, empty, corrupt, total
if exists and LOCAL_RANK in {-1, 0}:
- d = f"Scanning '{cache_path}' images and labels... {nf} found, {nm} missing, {ne} empty, {nc} corrupt"
- tqdm(None, desc=prefix + d, total=n, initial=n, bar_format=BAR_FORMAT) # display cache results
+ d = f"Scanning {cache_path}... {nf} images, {nm + ne} backgrounds, {nc} corrupt"
+ tqdm(None, desc=prefix + d, total=n, initial=n, bar_format=TQDM_BAR_FORMAT) # display cache results
if cache['msgs']:
LOGGER.info('\n'.join(cache['msgs'])) # display warnings
assert nf > 0 or not augment, f'{prefix}No labels found in {cache_path}, can not start training. {HELP_URL}'
@@ -505,7 +510,19 @@ class LoadImagesAndLabels(Dataset):
self.shapes = np.array(shapes)
self.im_files = list(cache.keys()) # update
self.label_files = img2label_paths(cache.keys()) # update
- n = len(shapes) # number of images
+
+ # Filter images
+ if min_items:
+ include = np.array([len(x) >= min_items for x in self.labels]).nonzero()[0].astype(int)
+ LOGGER.info(f'{prefix}{n - len(include)}/{n} images filtered from dataset')
+ self.im_files = [self.im_files[i] for i in include]
+ self.label_files = [self.label_files[i] for i in include]
+ self.labels = [self.labels[i] for i in include]
+ self.segments = [self.segments[i] for i in include]
+ self.shapes = self.shapes[include] # wh
+
+ # Create indices
+ n = len(self.shapes) # number of images
bi = np.floor(np.arange(n) / batch_size).astype(int) # batch index
nb = bi[-1] + 1 # number of batches
self.batch = bi # batch index of image
@@ -523,8 +540,6 @@ class LoadImagesAndLabels(Dataset):
self.segments[i] = segment[j]
if single_cls: # single-class training, merge all classes into 0
self.labels[i][:, 0] = 0
- if segment:
- self.segments[i][:, 0] = 0
# Rectangular Training
if self.rect:
@@ -551,34 +566,53 @@ class LoadImagesAndLabels(Dataset):
self.batch_shapes = np.ceil(np.array(shapes) * img_size / stride + pad).astype(int) * stride
- # Cache images into RAM/disk for faster training (WARNING: large datasets may exceed system resources)
+ # Cache images into RAM/disk for faster training
+ if cache_images == 'ram' and not self.check_cache_ram(prefix=prefix):
+ cache_images = False
self.ims = [None] * n
self.npy_files = [Path(f).with_suffix('.npy') for f in self.im_files]
if cache_images:
- gb = 0 # Gigabytes of cached images
+ b, gb = 0, 1 << 30 # bytes of cached images, bytes per gigabytes
self.im_hw0, self.im_hw = [None] * n, [None] * n
fcn = self.cache_images_to_disk if cache_images == 'disk' else self.load_image
results = ThreadPool(NUM_THREADS).imap(fcn, range(n))
- pbar = tqdm(enumerate(results), total=n, bar_format=BAR_FORMAT, disable=LOCAL_RANK > 0)
+ pbar = tqdm(enumerate(results), total=n, bar_format=TQDM_BAR_FORMAT, disable=LOCAL_RANK > 0)
for i, x in pbar:
if cache_images == 'disk':
- gb += self.npy_files[i].stat().st_size
+ b += self.npy_files[i].stat().st_size
else: # 'ram'
self.ims[i], self.im_hw0[i], self.im_hw[i] = x # im, hw_orig, hw_resized = load_image(self, i)
- gb += self.ims[i].nbytes
- pbar.desc = f'{prefix}Caching images ({gb / 1E9:.1f}GB {cache_images})'
+ b += self.ims[i].nbytes
+ pbar.desc = f'{prefix}Caching images ({b / gb:.1f}GB {cache_images})'
pbar.close()
+ def check_cache_ram(self, safety_margin=0.1, prefix=''):
+ # Check image caching requirements vs available memory
+ b, gb = 0, 1 << 30 # bytes of cached images, bytes per gigabytes
+ n = min(self.n, 30) # extrapolate from 30 random images
+ for _ in range(n):
+ im = cv2.imread(random.choice(self.im_files)) # sample image
+ ratio = self.img_size / max(im.shape[0], im.shape[1]) # max(h, w) # ratio
+ b += im.nbytes * ratio ** 2
+ mem_required = b * self.n / n # GB required to cache dataset into RAM
+ mem = psutil.virtual_memory()
+ cache = mem_required * (1 + safety_margin) < mem.available # to cache or not to cache, that is the question
+ if not cache:
+ LOGGER.info(f"{prefix}{mem_required / gb:.1f}GB RAM required, "
+ f"{mem.available / gb:.1f}/{mem.total / gb:.1f}GB available, "
+ f"{'caching images ✅' if cache else 'not caching images ⚠️'}")
+ return cache
+
def cache_labels(self, path=Path('./labels.cache'), prefix=''):
# Cache dataset labels, check images and read shapes
x = {} # dict
nm, nf, ne, nc, msgs = 0, 0, 0, 0, [] # number missing, found, empty, corrupt, messages
- desc = f"{prefix}Scanning '{path.parent / path.stem}' images and labels..."
+ desc = f"{prefix}Scanning {path.parent / path.stem}..."
with Pool(NUM_THREADS) as pool:
pbar = tqdm(pool.imap(verify_image_label, zip(self.im_files, self.label_files, repeat(prefix))),
desc=desc,
total=len(self.im_files),
- bar_format=BAR_FORMAT)
+ bar_format=TQDM_BAR_FORMAT)
for im_file, lb, shape, segments, nm_f, nf_f, ne_f, nc_f, msg in pbar:
nm += nm_f
nf += nf_f
@@ -588,7 +622,7 @@ class LoadImagesAndLabels(Dataset):
x[im_file] = [lb, shape, segments]
if msg:
msgs.append(msg)
- pbar.desc = f"{desc}{nf} found, {nm} missing, {ne} empty, {nc} corrupt"
+ pbar.desc = f"{desc} {nf} images, {nm + ne} backgrounds, {nc} corrupt"
pbar.close()
if msgs:
@@ -703,7 +737,7 @@ class LoadImagesAndLabels(Dataset):
r = self.img_size / max(h0, w0) # ratio
if r != 1: # if sizes are not equal
interp = cv2.INTER_LINEAR if (self.augment or r > 1) else cv2.INTER_AREA
- im = cv2.resize(im, (int(w0 * r), int(h0 * r)), interpolation=interp)
+ im = cv2.resize(im, (math.ceil(w0 * r), math.ceil(h0 * r)), interpolation=interp)
return im, (h0, w0), im.shape[:2] # im, hw_original, hw_resized
return self.ims[i], self.im_hw0[i], self.im_hw[i] # im, hw_original, hw_resized
@@ -835,6 +869,7 @@ class LoadImagesAndLabels(Dataset):
# img9, labels9 = replicate(img9, labels9) # replicate
# Augment
+ img9, labels9, segments9 = copy_paste(img9, labels9, segments9, p=self.hyp['copy_paste'])
img9, labels9 = random_perspective(img9,
labels9,
segments9,
@@ -1005,13 +1040,18 @@ def verify_image_label(args):
class HUBDatasetStats():
- """ Return dataset statistics dictionary with images and instances counts per split per class
- To run in parent directory: export PYTHONPATH="$PWD/yolov5"
- Usage1: from utils.dataloaders import *; HUBDatasetStats('coco128.yaml', autodownload=True)
- Usage2: from utils.dataloaders import *; HUBDatasetStats('path/to/coco128_with_yaml.zip')
+ """ Class for generating HUB dataset JSON and `-hub` dataset directory
+
Arguments
path: Path to data.yaml or data.zip (with data.yaml inside data.zip)
autodownload: Attempt to download dataset if not found locally
+
+ Usage
+ from utils.dataloaders import HUBDatasetStats
+ stats = HUBDatasetStats('coco128.yaml', autodownload=True) # usage 1
+ stats = HUBDatasetStats('path/to/coco128.zip') # usage 2
+ stats.get_json(save=False)
+ stats.process_images()
"""
def __init__(self, path='coco128.yaml', autodownload=False):
@@ -1048,7 +1088,7 @@ class HUBDatasetStats():
if not str(path).endswith('.zip'): # path is data.yaml
return False, None, path
assert Path(path).is_file(), f'Error unzipping {path}, file not found'
- ZipFile(path).extractall(path=path.parent) # unzip
+ unzip_file(path, path=path.parent)
dir = path.with_suffix('') # dataset directory == zip name
assert dir.is_dir(), f'Error unzipping {path}, {dir} not found. path/to/abc.zip MUST unzip to path/to/abc/'
return True, str(dir), self._find_yaml(dir) # zipped, data_dir, yaml_path
diff --git a/utils/docker/.dockerignore b/utils/docker/.dockerignore
deleted file mode 100644
index af51ccc..0000000
--- a/utils/docker/.dockerignore
+++ /dev/null
@@ -1,222 +0,0 @@
-# Repo-specific DockerIgnore -------------------------------------------------------------------------------------------
-#.git
-.cache
-.idea
-runs
-output
-coco
-storage.googleapis.com
-
-data/samples/*
-**/results*.csv
-*.jpg
-
-# Neural Network weights -----------------------------------------------------------------------------------------------
-**/*.pt
-**/*.pth
-**/*.onnx
-**/*.engine
-**/*.mlmodel
-**/*.torchscript
-**/*.torchscript.pt
-**/*.tflite
-**/*.h5
-**/*.pb
-*_saved_model/
-*_web_model/
-*_openvino_model/
-
-# Below Copied From .gitignore -----------------------------------------------------------------------------------------
-# Below Copied From .gitignore -----------------------------------------------------------------------------------------
-
-
-# GitHub Python GitIgnore ----------------------------------------------------------------------------------------------
-# Byte-compiled / optimized / DLL files
-__pycache__/
-*.py[cod]
-*$py.class
-
-# C extensions
-*.so
-
-# Distribution / packaging
-.Python
-env/
-build/
-develop-eggs/
-dist/
-downloads/
-eggs/
-.eggs/
-lib/
-lib64/
-parts/
-sdist/
-var/
-wheels/
-*.egg-info/
-wandb/
-.installed.cfg
-*.egg
-
-# PyInstaller
-# Usually these files are written by a python script from a template
-# before PyInstaller builds the exe, so as to inject date/other infos into it.
-*.manifest
-*.spec
-
-# Installer logs
-pip-log.txt
-pip-delete-this-directory.txt
-
-# Unit test / coverage reports
-htmlcov/
-.tox/
-.coverage
-.coverage.*
-.cache
-nosetests.xml
-coverage.xml
-*.cover
-.hypothesis/
-
-# Translations
-*.mo
-*.pot
-
-# Django stuff:
-*.log
-local_settings.py
-
-# Flask stuff:
-instance/
-.webassets-cache
-
-# Scrapy stuff:
-.scrapy
-
-# Sphinx documentation
-docs/_build/
-
-# PyBuilder
-target/
-
-# Jupyter Notebook
-.ipynb_checkpoints
-
-# pyenv
-.python-version
-
-# celery beat schedule file
-celerybeat-schedule
-
-# SageMath parsed files
-*.sage.py
-
-# dotenv
-.env
-
-# virtualenv
-.venv*
-venv*/
-ENV*/
-
-# Spyder project settings
-.spyderproject
-.spyproject
-
-# Rope project settings
-.ropeproject
-
-# mkdocs documentation
-/site
-
-# mypy
-.mypy_cache/
-
-
-# https://github.com/github/gitignore/blob/master/Global/macOS.gitignore -----------------------------------------------
-
-# General
-.DS_Store
-.AppleDouble
-.LSOverride
-
-# Icon must end with two \r
-Icon
-Icon?
-
-# Thumbnails
-._*
-
-# Files that might appear in the root of a volume
-.DocumentRevisions-V100
-.fseventsd
-.Spotlight-V100
-.TemporaryItems
-.Trashes
-.VolumeIcon.icns
-.com.apple.timemachine.donotpresent
-
-# Directories potentially created on remote AFP share
-.AppleDB
-.AppleDesktop
-Network Trash Folder
-Temporary Items
-.apdisk
-
-
-# https://github.com/github/gitignore/blob/master/Global/JetBrains.gitignore
-# Covers JetBrains IDEs: IntelliJ, RubyMine, PhpStorm, AppCode, PyCharm, CLion, Android Studio and WebStorm
-# Reference: https://intellij-support.jetbrains.com/hc/en-us/articles/206544839
-
-# User-specific stuff:
-.idea/*
-.idea/**/workspace.xml
-.idea/**/tasks.xml
-.idea/dictionaries
-.html # Bokeh Plots
-.pg # TensorFlow Frozen Graphs
-.avi # videos
-
-# Sensitive or high-churn files:
-.idea/**/dataSources/
-.idea/**/dataSources.ids
-.idea/**/dataSources.local.xml
-.idea/**/sqlDataSources.xml
-.idea/**/dynamic.xml
-.idea/**/uiDesigner.xml
-
-# Gradle:
-.idea/**/gradle.xml
-.idea/**/libraries
-
-# CMake
-cmake-build-debug/
-cmake-build-release/
-
-# Mongo Explorer plugin:
-.idea/**/mongoSettings.xml
-
-## File-based project format:
-*.iws
-
-## Plugin-specific files:
-
-# IntelliJ
-out/
-
-# mpeltonen/sbt-idea plugin
-.idea_modules/
-
-# JIRA plugin
-atlassian-ide-plugin.xml
-
-# Cursive Clojure plugin
-.idea/replstate.xml
-
-# Crashlytics plugin (for Android Studio and IntelliJ)
-com_crashlytics_export_strings.xml
-crashlytics.properties
-crashlytics-build.properties
-fabric.properties
diff --git a/utils/docker/Dockerfile b/utils/docker/Dockerfile
index 764ee27..98e9c29 100644
--- a/utils/docker/Dockerfile
+++ b/utils/docker/Dockerfile
@@ -3,7 +3,7 @@
# Image is CUDA-optimized for YOLOv5 single/multi-GPU training and inference
# Start FROM NVIDIA PyTorch image https://ngc.nvidia.com/catalog/containers/nvidia:pytorch
-FROM nvcr.io/nvidia/pytorch:22.08-py3
+FROM nvcr.io/nvidia/pytorch:22.12-py3
RUN rm -rf /opt/pytorch # remove 1.2GB dir
# Downloads to user config dir
@@ -12,12 +12,13 @@ ADD https://ultralytics.com/assets/Arial.ttf https://ultralytics.com/assets/Aria
# Install linux packages
RUN apt update && apt install --no-install-recommends -y zip htop screen libgl1-mesa-glx
-# Install pip packages
+# Install pip packages (uninstall torch nightly in favor of stable)
COPY requirements.txt .
RUN python -m pip install --upgrade pip wheel
RUN pip uninstall -y Pillow torchtext torch torchvision
-RUN pip install --no-cache -r requirements.txt albumentations wandb gsutil notebook Pillow>=9.1.0 \
- 'opencv-python<4.6.0.66' \
+RUN pip install --no-cache -U pycocotools # install --upgrade
+RUN pip install --no-cache -r requirements.txt albumentations comet gsutil notebook 'opencv-python<4.6.0.66' \
+ Pillow>=9.1.0 ultralytics \
--extra-index-url https://download.pytorch.org/whl/cu113
# Create working directory
@@ -29,7 +30,7 @@ WORKDIR /usr/src/app
RUN git clone https://github.com/ultralytics/yolov5 /usr/src/app
# Set environment variables
-ENV OMP_NUM_THREADS=8
+ENV OMP_NUM_THREADS=1
# Usage Examples -------------------------------------------------------------------------------------------------------
diff --git a/utils/docker/Dockerfile-arm64 b/utils/docker/Dockerfile-arm64
index 6e8ff77..eed1410 100644
--- a/utils/docker/Dockerfile-arm64
+++ b/utils/docker/Dockerfile-arm64
@@ -9,15 +9,16 @@ FROM arm64v8/ubuntu:20.04
ADD https://ultralytics.com/assets/Arial.ttf https://ultralytics.com/assets/Arial.Unicode.ttf /root/.config/Ultralytics/
# Install linux packages
+ENV DEBIAN_FRONTEND noninteractive
RUN apt update
-RUN DEBIAN_FRONTEND=noninteractive TZ=Etc/UTC apt install -y tzdata
+RUN TZ=Etc/UTC apt install -y tzdata
RUN apt install --no-install-recommends -y python3-pip git zip curl htop gcc libgl1-mesa-glx libglib2.0-0 libpython3-dev
# RUN alias python=python3
# Install pip packages
COPY requirements.txt .
RUN python3 -m pip install --upgrade pip wheel
-RUN pip install --no-cache -r requirements.txt gsutil notebook \
+RUN pip install --no-cache -r requirements.txt ultralytics gsutil notebook \
tensorflow-aarch64
# tensorflowjs \
# onnx onnx-simplifier onnxruntime \
@@ -30,12 +31,13 @@ WORKDIR /usr/src/app
# Copy contents
# COPY . /usr/src/app (issues as not a .git directory)
RUN git clone https://github.com/ultralytics/yolov5 /usr/src/app
+ENV DEBIAN_FRONTEND teletype
# Usage Examples -------------------------------------------------------------------------------------------------------
# Build and Push
-# t=ultralytics/yolov5:latest-M1 && sudo docker build --platform linux/arm64 -f utils/docker/Dockerfile-arm64 -t $t . && sudo docker push $t
+# t=ultralytics/yolov5:latest-arm64 && sudo docker build --platform linux/arm64 -f utils/docker/Dockerfile-arm64 -t $t . && sudo docker push $t
# Pull and Run
-# t=ultralytics/yolov5:latest-M1 && sudo docker pull $t && sudo docker run -it --ipc=host -v "$(pwd)"/datasets:/usr/src/datasets $t
+# t=ultralytics/yolov5:latest-arm64 && sudo docker pull $t && sudo docker run -it --ipc=host -v "$(pwd)"/datasets:/usr/src/datasets $t
diff --git a/utils/docker/Dockerfile-cpu b/utils/docker/Dockerfile-cpu
index d6fac64..558f81f 100644
--- a/utils/docker/Dockerfile-cpu
+++ b/utils/docker/Dockerfile-cpu
@@ -9,15 +9,16 @@ FROM ubuntu:20.04
ADD https://ultralytics.com/assets/Arial.ttf https://ultralytics.com/assets/Arial.Unicode.ttf /root/.config/Ultralytics/
# Install linux packages
+ENV DEBIAN_FRONTEND noninteractive
RUN apt update
-RUN DEBIAN_FRONTEND=noninteractive TZ=Etc/UTC apt install -y tzdata
-RUN apt install --no-install-recommends -y python3-pip git zip curl htop libgl1-mesa-glx libglib2.0-0 libpython3-dev
+RUN TZ=Etc/UTC apt install -y tzdata
+RUN apt install --no-install-recommends -y python3-pip git zip curl htop libgl1-mesa-glx libglib2.0-0 libpython3-dev gnupg
# RUN alias python=python3
# Install pip packages
COPY requirements.txt .
RUN python3 -m pip install --upgrade pip wheel
-RUN pip install --no-cache -r requirements.txt albumentations gsutil notebook \
+RUN pip install --no-cache -r requirements.txt ultralytics albumentations gsutil notebook \
coremltools onnx onnx-simplifier onnxruntime tensorflow-cpu tensorflowjs \
# openvino-dev \
--extra-index-url https://download.pytorch.org/whl/cpu
@@ -29,6 +30,7 @@ WORKDIR /usr/src/app
# Copy contents
# COPY . /usr/src/app (issues as not a .git directory)
RUN git clone https://github.com/ultralytics/yolov5 /usr/src/app
+ENV DEBIAN_FRONTEND teletype
# Usage Examples -------------------------------------------------------------------------------------------------------
diff --git a/utils/downloads.py b/utils/downloads.py
index 73b8334..72ea873 100644
--- a/utils/downloads.py
+++ b/utils/downloads.py
@@ -5,12 +5,9 @@ Download utils
import logging
import os
-import platform
import subprocess
-import time
import urllib
from pathlib import Path
-from zipfile import ZipFile
import requests
import torch
@@ -21,7 +18,7 @@ def is_url(url, check=True):
try:
url = str(url)
result = urllib.parse.urlparse(url)
- assert all([result.scheme, result.netloc, result.path]) # check if is url
+ assert all([result.scheme, result.netloc]) # check if is url
return (urllib.request.urlopen(url).getcode() == 200) if check else True # check if exists online
except (AssertionError, urllib.request.HTTPError):
return False
@@ -62,14 +59,14 @@ def safe_download(file, url, url2=None, min_bytes=1E0, error_msg=''):
LOGGER.info('')
-def attempt_download(file, repo='ultralytics/yolov5', release='v6.2'):
- # Attempt file download from GitHub release assets if not found locally. release = 'latest', 'v6.2', etc.
+def attempt_download(file, repo='ultralytics/yolov5', release='v7.0'):
+ # Attempt file download from GitHub release assets if not found locally. release = 'latest', 'v7.0', etc.
from utils.general import LOGGER
def github_assets(repository, version='latest'):
- # Return GitHub repo tag (i.e. 'v6.2') and assets (i.e. ['yolov5s.pt', 'yolov5m.pt', ...])
+ # Return GitHub repo tag (i.e. 'v7.0') and assets (i.e. ['yolov5s.pt', 'yolov5m.pt', ...])
if version != 'latest':
- version = f'tags/{version}' # i.e. tags/v6.2
+ version = f'tags/{version}' # i.e. tags/v7.0
response = requests.get(f'https://api.github.com/repos/{repository}/releases/{version}').json() # github api
return response['tag_name'], [x['name'] for x in response['assets']] # tag, assets
@@ -109,81 +106,3 @@ def attempt_download(file, repo='ultralytics/yolov5', release='v6.2'):
error_msg=f'{file} missing, try downloading from https://github.com/{repo}/releases/{tag} or {url3}')
return str(file)
-
-
-def gdrive_download(id='16TiPfZj7htmTyhntwcZyEEAejOUxuT6m', file='tmp.zip'):
- # Downloads a file from Google Drive. from yolov5.utils.downloads import *; gdrive_download()
- t = time.time()
- file = Path(file)
- cookie = Path('cookie') # gdrive cookie
- print(f'Downloading https://drive.google.com/uc?export=download&id={id} as {file}... ', end='')
- if file.exists():
- file.unlink() # remove existing file
- if cookie.exists():
- cookie.unlink() # remove existing cookie
-
- # Attempt file download
- out = "NUL" if platform.system() == "Windows" else "/dev/null"
- os.system(f'curl -c ./cookie -s -L "drive.google.com/uc?export=download&id={id}" > {out}')
- if os.path.exists('cookie'): # large file
- s = f'curl -Lb ./cookie "drive.google.com/uc?export=download&confirm={get_token()}&id={id}" -o {file}'
- else: # small file
- s = f'curl -s -L -o {file} "drive.google.com/uc?export=download&id={id}"'
- r = os.system(s) # execute, capture return
- if cookie.exists():
- cookie.unlink() # remove existing cookie
-
- # Error check
- if r != 0:
- if file.exists():
- file.unlink() # remove partial
- print('Download error ') # raise Exception('Download error')
- return r
-
- # Unzip if archive
- if file.suffix == '.zip':
- print('unzipping... ', end='')
- ZipFile(file).extractall(path=file.parent) # unzip
- file.unlink() # remove zip
-
- print(f'Done ({time.time() - t:.1f}s)')
- return r
-
-
-def get_token(cookie="./cookie"):
- with open(cookie) as f:
- for line in f:
- if "download" in line:
- return line.split()[-1]
- return ""
-
-
-# Google utils: https://cloud.google.com/storage/docs/reference/libraries ----------------------------------------------
-#
-#
-# def upload_blob(bucket_name, source_file_name, destination_blob_name):
-# # Uploads a file to a bucket
-# # https://cloud.google.com/storage/docs/uploading-objects#storage-upload-object-python
-#
-# storage_client = storage.Client()
-# bucket = storage_client.get_bucket(bucket_name)
-# blob = bucket.blob(destination_blob_name)
-#
-# blob.upload_from_filename(source_file_name)
-#
-# print('File {} uploaded to {}.'.format(
-# source_file_name,
-# destination_blob_name))
-#
-#
-# def download_blob(bucket_name, source_blob_name, destination_file_name):
-# # Uploads a blob from a bucket
-# storage_client = storage.Client()
-# bucket = storage_client.get_bucket(bucket_name)
-# blob = bucket.blob(source_blob_name)
-#
-# blob.download_to_filename(destination_file_name)
-#
-# print('Blob {} downloaded to {}.'.format(
-# source_blob_name,
-# destination_file_name))
diff --git a/utils/general.py b/utils/general.py
index c451914..0bbcb6e 100644
--- a/utils/general.py
+++ b/utils/general.py
@@ -7,12 +7,12 @@ import contextlib
import glob
import inspect
import logging
+import logging.config
import math
import os
import platform
import random
import re
-import shutil
import signal
import sys
import time
@@ -23,8 +23,9 @@ from itertools import repeat
from multiprocessing.pool import ThreadPool
from pathlib import Path
from subprocess import check_output
+from tarfile import is_tarfile
from typing import Optional
-from zipfile import ZipFile
+from zipfile import ZipFile, is_zipfile
import cv2
import IPython
@@ -48,6 +49,7 @@ NUM_THREADS = min(8, max(1, os.cpu_count() - 1)) # number of YOLOv5 multiproces
DATASETS_DIR = Path(os.getenv('YOLOv5_DATASETS_DIR', ROOT.parent / 'datasets')) # global datasets directory
AUTOINSTALL = str(os.getenv('YOLOv5_AUTOINSTALL', True)).lower() == 'true' # global auto-install mode
VERBOSE = str(os.getenv('YOLOv5_VERBOSE', True)).lower() == 'true' # global verbose mode
+TQDM_BAR_FORMAT = '{l_bar}{bar:10}{r_bar}' # tqdm bar format
FONT = 'Arial.ttf' # https://ultralytics.com/assets/Arial.ttf
torch.set_printoptions(linewidth=320, precision=5, profile='long')
@@ -71,7 +73,13 @@ def is_chinese(s='人工智能'):
def is_colab():
# Is environment a Google Colab instance?
- return 'COLAB_GPU' in os.environ
+ return 'google.colab' in sys.modules
+
+
+def is_notebook():
+ # Is environment a Jupyter notebook? Verified on Colab, Jupyterlab, Kaggle, Paperspace
+ ipython_type = str(type(IPython.get_ipython()))
+ return 'colab' in ipython_type or 'zmqshell' in ipython_type
def is_kaggle():
@@ -104,23 +112,33 @@ def is_writeable(dir, test=False):
return False
-def set_logging(name=None, verbose=VERBOSE):
- # Sets level and returns logger
- if is_kaggle() or is_colab():
- for h in logging.root.handlers:
- logging.root.removeHandler(h) # remove all handlers associated with the root logger object
+LOGGING_NAME = "yolov5"
+
+
+def set_logging(name=LOGGING_NAME, verbose=True):
+ # sets up logging for the given name
rank = int(os.getenv('RANK', -1)) # rank in world for Multi-GPU trainings
level = logging.INFO if verbose and rank in {-1, 0} else logging.ERROR
- log = logging.getLogger(name)
- log.setLevel(level)
- handler = logging.StreamHandler()
- handler.setFormatter(logging.Formatter("%(message)s"))
- handler.setLevel(level)
- log.addHandler(handler)
+ logging.config.dictConfig({
+ "version": 1,
+ "disable_existing_loggers": False,
+ "formatters": {
+ name: {
+ "format": "%(message)s"}},
+ "handlers": {
+ name: {
+ "class": "logging.StreamHandler",
+ "formatter": name,
+ "level": level,}},
+ "loggers": {
+ name: {
+ "level": level,
+ "handlers": [name],
+ "propagate": False,}}})
-set_logging() # run before defining LOGGER
-LOGGER = logging.getLogger("yolov5") # define globally (used in train.py, val.py, detect.py, etc.)
+set_logging(LOGGING_NAME) # run before defining LOGGER
+LOGGER = logging.getLogger(LOGGING_NAME) # define globally (used in train.py, val.py, detect.py, etc.)
if platform.system() == 'Windows':
for fn in LOGGER.info, LOGGER.warning:
setattr(LOGGER, fn.__name__, lambda x: fn(emojis(x))) # emoji safe logging
@@ -138,11 +156,6 @@ def user_config_dir(dir='Ultralytics', env_var='YOLOV5_CONFIG_DIR'):
path.mkdir(exist_ok=True) # make if required
return path
-def is_notebook():
- # Is environment a Jupyter notebook? Verified on Colab, Jupyterlab, Kaggle, Paperspace
- ipython_type = str(type(IPython.get_ipython()))
- return 'colab' in ipython_type or 'zmqshell' in ipython_type
-
CONFIG_DIR = user_config_dir() # Ultralytics settings dir
@@ -281,11 +294,16 @@ def file_size(path):
def check_online():
# Check internet connectivity
import socket
- try:
- socket.create_connection(("1.1.1.1", 443), 5) # check host accessibility
- return True
- except OSError:
- return False
+
+ def run_once():
+ # Check once
+ try:
+ socket.create_connection(("1.1.1.1", 443), 5) # check host accessibility
+ return True
+ except OSError:
+ return False
+
+ return run_once() or run_once() # check twice to increase robustness to intermittent connectivity issues
def git_describe(path=ROOT): # path must be a directory
@@ -325,6 +343,24 @@ def check_git_status(repo='ultralytics/yolov5', branch='master'):
LOGGER.info(s)
+@WorkingDirectory(ROOT)
+def check_git_info(path='.'):
+ # YOLOv5 git info check, return {remote, branch, commit}
+ check_requirements('gitpython')
+ import git
+ try:
+ repo = git.Repo(path)
+ remote = repo.remotes.origin.url.replace('.git', '') # i.e. 'https://github.com/ultralytics/yolov5'
+ commit = repo.head.commit.hexsha # i.e. '3134699c73af83aac2a481435550b968d5792c0d'
+ try:
+ branch = repo.active_branch.name # i.e. 'main'
+ except TypeError: # not on any branch
+ branch = None # i.e. 'detached HEAD' state
+ return {'remote': remote, 'branch': branch, 'commit': commit}
+ except git.exc.InvalidGitRepositoryError: # path is not a git dir
+ return {'remote': None, 'branch': None, 'commit': None}
+
+
def check_python(minimum='3.7.0'):
# Check current python version vs. required python version
check_version(platform.python_version(), minimum, name='Python ', hard=True)
@@ -367,7 +403,7 @@ def check_requirements(requirements=ROOT / 'requirements.txt', exclude=(), insta
if s and install and AUTOINSTALL: # check environment variable
LOGGER.info(f"{prefix} YOLOv5 requirement{'s' * (n > 1)} {s}not found, attempting AutoUpdate...")
try:
- assert check_online(), "AutoUpdate skipped (offline)"
+ # assert check_online(), "AutoUpdate skipped (offline)"
LOGGER.info(check_output(f'pip install {s} {cmds}', shell=True).decode())
source = file if 'file' in locals() else requirements
s = f"{prefix} {n} package{'s' * (n > 1)} updated per {source}\n" \
@@ -389,18 +425,19 @@ def check_img_size(imgsz, s=32, floor=0):
return new_size
-def check_imshow():
+def check_imshow(warn=False):
# Check if environment supports image displays
try:
- assert not is_docker(), 'cv2.imshow() is disabled in Docker environments'
- assert not is_colab(), 'cv2.imshow() is disabled in Google Colab environments'
+ assert not is_notebook()
+ assert not is_docker()
cv2.imshow('test', np.zeros((1, 1, 3)))
cv2.waitKey(1)
cv2.destroyAllWindows()
cv2.waitKey(1)
return True
except Exception as e:
- LOGGER.warning(f'WARNING ⚠️ Environment does not support cv2.imshow() or PIL Image.show() image displays\n{e}')
+ if warn:
+ LOGGER.warning(f'WARNING ⚠️ Environment does not support cv2.imshow() or PIL Image.show()\n{e}')
return False
@@ -424,12 +461,12 @@ def check_file(file, suffix=''):
# Search/download file (if necessary) and return path
check_suffix(file, suffix) # optional
file = str(file) # convert to str()
- if Path(file).is_file() or not file: # exists
+ if os.path.isfile(file) or not file: # exists
return file
elif file.startswith(('http:/', 'https:/')): # download
url = file # warning: Pathlib turns :// -> :/
file = Path(urllib.parse.unquote(file).split('?')[0]).name # '%2F' to '/', split https://url.com/file.txt?auth
- if Path(file).is_file():
+ if os.path.isfile(file):
LOGGER.info(f'Found {url} locally at {file}') # file already exists
else:
LOGGER.info(f'Downloading {url} to {file}...')
@@ -463,7 +500,7 @@ def check_dataset(data, autodownload=True):
# Download (optional)
extract_dir = ''
- if isinstance(data, (str, Path)) and str(data).endswith('.zip'): # i.e. gs://bucket/dir/coco128.zip
+ if isinstance(data, (str, Path)) and (is_zipfile(data) or is_tarfile(data)):
download(data, dir=f'{DATASETS_DIR}/{Path(data).stem}', unzip=True, delete=False, curl=False, threads=1)
data = next((DATASETS_DIR / Path(data).stem).rglob('*.yaml'))
extract_dir, autodownload = data.parent, False
@@ -474,15 +511,17 @@ def check_dataset(data, autodownload=True):
# Checks
for k in 'train', 'val', 'names':
- assert k in data, f"data.yaml '{k}:' field missing ❌"
+ assert k in data, emojis(f"data.yaml '{k}:' field missing ❌")
if isinstance(data['names'], (list, tuple)): # old array format
data['names'] = dict(enumerate(data['names'])) # convert to dict
+ assert all(isinstance(k, int) for k in data['names'].keys()), 'data.yaml names keys must be integers, i.e. 2: car'
data['nc'] = len(data['names'])
# Resolve paths
path = Path(extract_dir or data.get('path') or '') # optional 'path' default to '.'
if not path.is_absolute():
path = (ROOT / path).resolve()
+ data['path'] = path # download scripts
for k in 'train', 'val', 'test':
if data.get(k): # prepend path
if isinstance(data[k], str):
@@ -507,7 +546,7 @@ def check_dataset(data, autodownload=True):
LOGGER.info(f'Downloading {s} to {f}...')
torch.hub.download_url_to_file(s, f)
Path(DATASETS_DIR).mkdir(parents=True, exist_ok=True) # create root
- ZipFile(f).extractall(path=DATASETS_DIR) # unzip
+ unzip_file(f, path=DATASETS_DIR) # unzip
Path(f).unlink() # remove zip
r = None # success
elif s.startswith('bash '): # bash script
@@ -562,6 +601,16 @@ def yaml_save(file='data.yaml', data={}):
yaml.safe_dump({k: str(v) if isinstance(v, Path) else v for k, v in data.items()}, f, sort_keys=False)
+def unzip_file(file, path=None, exclude=('.DS_Store', '__MACOSX')):
+ # Unzip a *.zip file to path/, excluding files containing strings in exclude list
+ if path is None:
+ path = Path(file).parent # default path
+ with ZipFile(file) as zipObj:
+ for f in zipObj.namelist(): # list all archived filenames in the zip
+ if all(x not in f for x in exclude):
+ zipObj.extract(f, path=path)
+
+
def url2file(url):
# Convert URL to filename, i.e. https://url.com/file.txt?auth -> file.txt
url = str(Path(url)).replace(':/', '://') # Pathlib turns :// -> :/
@@ -573,7 +622,7 @@ def download(url, dir='.', unzip=True, delete=True, curl=False, threads=1, retry
def download_one(url, dir):
# Download 1 file
success = True
- if Path(url).is_file():
+ if os.path.isfile(url):
f = Path(url) # filename
else: # does not exist
f = dir / Path(url).name
@@ -594,11 +643,11 @@ def download(url, dir='.', unzip=True, delete=True, curl=False, threads=1, retry
else:
LOGGER.warning(f'❌ Failed to download {url}...')
- if unzip and success and f.suffix in ('.zip', '.tar', '.gz'):
+ if unzip and success and (f.suffix == '.gz' or is_zipfile(f) or is_tarfile(f)):
LOGGER.info(f'Unzipping {f}...')
- if f.suffix == '.zip':
- ZipFile(f).extractall(path=dir) # unzip
- elif f.suffix == '.tar':
+ if is_zipfile(f):
+ unzip_file(f, dir) # unzip
+ elif is_tarfile(f):
os.system(f'tar xf {f} --directory {f.parent}') # unzip
elif f.suffix == '.gz':
os.system(f'tar xfz {f} --directory {f.parent}') # unzip
@@ -701,30 +750,30 @@ def coco80_to_coco91_class(): # converts 80-index (val2014) to 91-index (paper)
def xyxy2xywh(x):
# Convert nx4 boxes from [x1, y1, x2, y2] to [x, y, w, h] where xy1=top-left, xy2=bottom-right
y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
- y[:, 0] = (x[:, 0] + x[:, 2]) / 2 # x center
- y[:, 1] = (x[:, 1] + x[:, 3]) / 2 # y center
- y[:, 2] = x[:, 2] - x[:, 0] # width
- y[:, 3] = x[:, 3] - x[:, 1] # height
+ y[..., 0] = (x[..., 0] + x[..., 2]) / 2 # x center
+ y[..., 1] = (x[..., 1] + x[..., 3]) / 2 # y center
+ y[..., 2] = x[..., 2] - x[..., 0] # width
+ y[..., 3] = x[..., 3] - x[..., 1] # height
return y
def xywh2xyxy(x):
# Convert nx4 boxes from [x, y, w, h] to [x1, y1, x2, y2] where xy1=top-left, xy2=bottom-right
y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
- y[:, 0] = x[:, 0] - x[:, 2] / 2 # top left x
- y[:, 1] = x[:, 1] - x[:, 3] / 2 # top left y
- y[:, 2] = x[:, 0] + x[:, 2] / 2 # bottom right x
- y[:, 3] = x[:, 1] + x[:, 3] / 2 # bottom right y
+ y[..., 0] = x[..., 0] - x[..., 2] / 2 # top left x
+ y[..., 1] = x[..., 1] - x[..., 3] / 2 # top left y
+ y[..., 2] = x[..., 0] + x[..., 2] / 2 # bottom right x
+ y[..., 3] = x[..., 1] + x[..., 3] / 2 # bottom right y
return y
def xywhn2xyxy(x, w=640, h=640, padw=0, padh=0):
# Convert nx4 boxes from [x, y, w, h] normalized to [x1, y1, x2, y2] where xy1=top-left, xy2=bottom-right
y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
- y[:, 0] = w * (x[:, 0] - x[:, 2] / 2) + padw # top left x
- y[:, 1] = h * (x[:, 1] - x[:, 3] / 2) + padh # top left y
- y[:, 2] = w * (x[:, 0] + x[:, 2] / 2) + padw # bottom right x
- y[:, 3] = h * (x[:, 1] + x[:, 3] / 2) + padh # bottom right y
+ y[..., 0] = w * (x[..., 0] - x[..., 2] / 2) + padw # top left x
+ y[..., 1] = h * (x[..., 1] - x[..., 3] / 2) + padh # top left y
+ y[..., 2] = w * (x[..., 0] + x[..., 2] / 2) + padw # bottom right x
+ y[..., 3] = h * (x[..., 1] + x[..., 3] / 2) + padh # bottom right y
return y
@@ -733,18 +782,18 @@ def xyxy2xywhn(x, w=640, h=640, clip=False, eps=0.0):
if clip:
clip_boxes(x, (h - eps, w - eps)) # warning: inplace clip
y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
- y[:, 0] = ((x[:, 0] + x[:, 2]) / 2) / w # x center
- y[:, 1] = ((x[:, 1] + x[:, 3]) / 2) / h # y center
- y[:, 2] = (x[:, 2] - x[:, 0]) / w # width
- y[:, 3] = (x[:, 3] - x[:, 1]) / h # height
+ y[..., 0] = ((x[..., 0] + x[..., 2]) / 2) / w # x center
+ y[..., 1] = ((x[..., 1] + x[..., 3]) / 2) / h # y center
+ y[..., 2] = (x[..., 2] - x[..., 0]) / w # width
+ y[..., 3] = (x[..., 3] - x[..., 1]) / h # height
return y
def xyn2xy(x, w=640, h=640, padw=0, padh=0):
# Convert normalized segments into pixel segments, shape (n,2)
y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
- y[:, 0] = w * x[:, 0] + padw # top left x
- y[:, 1] = h * x[:, 1] + padh # top left y
+ y[..., 0] = w * x[..., 0] + padw # top left x
+ y[..., 1] = h * x[..., 1] + padh # top left y
return y
@@ -784,14 +833,14 @@ def scale_boxes(img1_shape, boxes, img0_shape, ratio_pad=None):
gain = ratio_pad[0][0]
pad = ratio_pad[1]
- boxes[:, [0, 2]] -= pad[0] # x padding
- boxes[:, [1, 3]] -= pad[1] # y padding
- boxes[:, :4] /= gain
+ boxes[..., [0, 2]] -= pad[0] # x padding
+ boxes[..., [1, 3]] -= pad[1] # y padding
+ boxes[..., :4] /= gain
clip_boxes(boxes, img0_shape)
return boxes
-def scale_segments(img1_shape, segments, img0_shape, ratio_pad=None):
+def scale_segments(img1_shape, segments, img0_shape, ratio_pad=None, normalize=False):
# Rescale coords (xyxy) from img1_shape to img0_shape
if ratio_pad is None: # calculate from img0_shape
gain = min(img1_shape[0] / img0_shape[0], img1_shape[1] / img0_shape[1]) # gain = old / new
@@ -804,29 +853,32 @@ def scale_segments(img1_shape, segments, img0_shape, ratio_pad=None):
segments[:, 1] -= pad[1] # y padding
segments /= gain
clip_segments(segments, img0_shape)
+ if normalize:
+ segments[:, 0] /= img0_shape[1] # width
+ segments[:, 1] /= img0_shape[0] # height
return segments
def clip_boxes(boxes, shape):
# Clip boxes (xyxy) to image shape (height, width)
if isinstance(boxes, torch.Tensor): # faster individually
- boxes[:, 0].clamp_(0, shape[1]) # x1
- boxes[:, 1].clamp_(0, shape[0]) # y1
- boxes[:, 2].clamp_(0, shape[1]) # x2
- boxes[:, 3].clamp_(0, shape[0]) # y2
+ boxes[..., 0].clamp_(0, shape[1]) # x1
+ boxes[..., 1].clamp_(0, shape[0]) # y1
+ boxes[..., 2].clamp_(0, shape[1]) # x2
+ boxes[..., 3].clamp_(0, shape[0]) # y2
else: # np.array (faster grouped)
- boxes[:, [0, 2]] = boxes[:, [0, 2]].clip(0, shape[1]) # x1, x2
- boxes[:, [1, 3]] = boxes[:, [1, 3]].clip(0, shape[0]) # y1, y2
+ boxes[..., [0, 2]] = boxes[..., [0, 2]].clip(0, shape[1]) # x1, x2
+ boxes[..., [1, 3]] = boxes[..., [1, 3]].clip(0, shape[0]) # y1, y2
-def clip_segments(boxes, shape):
+def clip_segments(segments, shape):
# Clip segments (xy1,xy2,...) to image shape (height, width)
- if isinstance(boxes, torch.Tensor): # faster individually
- boxes[:, 0].clamp_(0, shape[1]) # x
- boxes[:, 1].clamp_(0, shape[0]) # y
+ if isinstance(segments, torch.Tensor): # faster individually
+ segments[:, 0].clamp_(0, shape[1]) # x
+ segments[:, 1].clamp_(0, shape[0]) # y
else: # np.array (faster grouped)
- boxes[:, 0] = boxes[:, 0].clip(0, shape[1]) # x
- boxes[:, 1] = boxes[:, 1].clip(0, shape[0]) # y
+ segments[:, 0] = segments[:, 0].clip(0, shape[1]) # x
+ segments[:, 1] = segments[:, 1].clip(0, shape[0]) # y
def non_max_suppression(
@@ -846,16 +898,19 @@ def non_max_suppression(
list of detections, on (n,6) tensor per image [xyxy, conf, cls]
"""
- if isinstance(prediction, (list, tuple)): # YOLOv5 model in validation model, output = (inference_out, loss_out)
- prediction = prediction[0] # select only inference output
-
- bs = prediction.shape[0] # batch size
- nc = prediction.shape[2] - nm - 5 # number of classes
- xc = prediction[..., 4] > conf_thres # candidates
-
# Checks
assert 0 <= conf_thres <= 1, f'Invalid Confidence threshold {conf_thres}, valid values are between 0.0 and 1.0'
assert 0 <= iou_thres <= 1, f'Invalid IoU {iou_thres}, valid values are between 0.0 and 1.0'
+ if isinstance(prediction, (list, tuple)): # YOLOv5 model in validation model, output = (inference_out, loss_out)
+ prediction = prediction[0] # select only inference output
+
+ device = prediction.device
+ mps = 'mps' in device.type # Apple MPS
+ if mps: # MPS not fully supported yet, convert tensors to CPU before NMS
+ prediction = prediction.cpu()
+ bs = prediction.shape[0] # batch size
+ nc = prediction.shape[2] - nm - 5 # number of classes
+ xc = prediction[..., 4] > conf_thres # candidates
# Settings
# min_wh = 2 # (pixels) minimum box width and height
@@ -914,17 +969,13 @@ def non_max_suppression(
n = x.shape[0] # number of boxes
if not n: # no boxes
continue
- elif n > max_nms: # excess boxes
- x = x[x[:, 4].argsort(descending=True)[:max_nms]] # sort by confidence
- else:
- x = x[x[:, 4].argsort(descending=True)] # sort by confidence
+ x = x[x[:, 4].argsort(descending=True)[:max_nms]] # sort by confidence and remove excess boxes
# Batched NMS
c = x[:, 5:6] * (0 if agnostic else max_wh) # classes
boxes, scores = x[:, :4] + c, x[:, 4] # boxes (offset by class), scores
i = torchvision.ops.nms(boxes, scores, iou_thres) # NMS
- if i.shape[0] > max_det: # limit detections
- i = i[:max_det]
+ i = i[:max_det] # limit detections
if merge and (1 < n < 3E3): # Merge NMS (boxes merged using weighted mean)
# update boxes as boxes(i,4) = weights(i,n) * boxes(n,4)
iou = box_iou(boxes[i], boxes) > iou_thres # iou matrix
@@ -934,6 +985,8 @@ def non_max_suppression(
i = i[iou.sum(1) > 1] # require redundancy
output[xi] = x[i]
+ if mps:
+ output[xi] = output[xi].to(device)
if (time.time() - t) > time_limit:
LOGGER.warning(f'WARNING ⚠️ NMS time limit {time_limit:.3f}s exceeded')
break # time limit exceeded
@@ -946,7 +999,7 @@ def strip_optimizer(f='best.pt', s=''): # from utils.general import *; strip_op
x = torch.load(f, map_location=torch.device('cpu'))
if x.get('ema'):
x['model'] = x['ema'] # replace model with ema
- for k in 'optimizer', 'best_fitness', 'wandb_id', 'ema', 'updates': # keys
+ for k in 'optimizer', 'best_fitness', 'ema', 'updates': # keys
x[k] = None
x['epoch'] = -1
x['model'].half() # to FP16
@@ -957,11 +1010,10 @@ def strip_optimizer(f='best.pt', s=''): # from utils.general import *; strip_op
LOGGER.info(f"Optimizer stripped from {f},{f' saved as {s},' if s else ''} {mb:.1f}MB")
-def print_mutation(results, hyp, save_dir, bucket, prefix=colorstr('evolve: ')):
+def print_mutation(keys, results, hyp, save_dir, bucket, prefix=colorstr('evolve: ')):
evolve_csv = save_dir / 'evolve.csv'
evolve_yaml = save_dir / 'hyp_evolve.yaml'
- keys = ('metrics/precision', 'metrics/recall', 'metrics/mAP_0.5', 'metrics/mAP_0.5:0.95', 'val/box_loss',
- 'val/obj_loss', 'val/cls_loss') + tuple(hyp.keys()) # [results + hyps]
+ keys = tuple(keys) + tuple(hyp.keys()) # [results + hyps]
keys = tuple(x.strip() for x in keys)
vals = results + tuple(hyp.values())
n = len(keys)
@@ -979,7 +1031,7 @@ def print_mutation(results, hyp, save_dir, bucket, prefix=colorstr('evolve: ')):
# Save yaml
with open(evolve_yaml, 'w') as f:
- data = pd.read_csv(evolve_csv)
+ data = pd.read_csv(evolve_csv, skipinitialspace=True)
data = data.rename(columns=lambda x: x.strip()) # strip keys
i = np.argmax(fitness(data.values[:, :4])) #
generations = len(data)
@@ -1058,7 +1110,7 @@ def increment_path(path, exist_ok=False, sep='', mkdir=False):
return path
-# OpenCV Chinese-friendly functions ------------------------------------------------------------------------------------
+# OpenCV Multilanguage-friendly functions ------------------------------------------------------------------------------------
imshow_ = cv2.imshow # copy to avoid recursion errors
@@ -1081,4 +1133,3 @@ def imshow(path, im):
cv2.imread, cv2.imwrite, cv2.imshow = imread, imwrite, imshow # redefine
# Variables ------------------------------------------------------------------------------------------------------------
-NCOLS = 0 if is_docker() else shutil.get_terminal_size().columns # terminal window size for tqdm
diff --git a/utils/loggers/__init__.py b/utils/loggers/__init__.py
index 941d09e..22da870 100644
--- a/utils/loggers/__init__.py
+++ b/utils/loggers/__init__.py
@@ -84,10 +84,10 @@ class Loggers():
self.csv = True # always log to csv
# Messages
- if not wandb:
- prefix = colorstr('Weights & Biases: ')
- s = f"{prefix}run 'pip install wandb' to automatically track and visualize YOLOv5 🚀 runs in Weights & Biases"
- self.logger.info(s)
+ # if not wandb:
+ # prefix = colorstr('Weights & Biases: ')
+ # s = f"{prefix}run 'pip install wandb' to automatically track and visualize YOLOv5 🚀 runs in Weights & Biases"
+ # self.logger.info(s)
if not clearml:
prefix = colorstr('ClearML: ')
s = f"{prefix}run 'pip install clearml' to automatically track, visualize and remotely train YOLOv5 🚀 in ClearML"
@@ -110,15 +110,22 @@ class Loggers():
self.opt.hyp = self.hyp # add hyperparameters
self.wandb = WandbLogger(self.opt, run_id)
# temp warn. because nested artifacts not supported after 0.12.10
- if pkg.parse_version(wandb.__version__) >= pkg.parse_version('0.12.11'):
- s = "YOLOv5 temporarily requires wandb version 0.12.10 or below. Some features may not work as expected."
- self.logger.warning(s)
+ # if pkg.parse_version(wandb.__version__) >= pkg.parse_version('0.12.11'):
+ # s = "YOLOv5 temporarily requires wandb version 0.12.10 or below. Some features may not work as expected."
+ # self.logger.warning(s)
else:
self.wandb = None
# ClearML
if clearml and 'clearml' in self.include:
- self.clearml = ClearmlLogger(self.opt, self.hyp)
+ try:
+ self.clearml = ClearmlLogger(self.opt, self.hyp)
+ except Exception:
+ self.clearml = None
+ prefix = colorstr('ClearML: ')
+ LOGGER.warning(f'{prefix}WARNING ⚠️ ClearML is installed but not configured, skipping ClearML logging.'
+ f' See https://github.com/ultralytics/yolov5/tree/master/utils/loggers/clearml#readme')
+
else:
self.clearml = None
diff --git a/utils/loggers/clearml/README.md b/utils/loggers/clearml/README.md
index 64eef6b..3cf4c26 100644
--- a/utils/loggers/clearml/README.md
+++ b/utils/loggers/clearml/README.md
@@ -54,15 +54,23 @@ That's it! You're done 😎
To enable ClearML experiment tracking, simply install the ClearML pip package.
```bash
-pip install clearml
+pip install clearml>=1.2.0
```
-This will enable integration with the YOLOv5 training script. Every training run from now on, will be captured and stored by the ClearML experiment manager. If you want to change the `project_name` or `task_name`, head over to our custom logger, where you can change it: `utils/loggers/clearml/clearml_utils.py`
+This will enable integration with the YOLOv5 training script. Every training run from now on, will be captured and stored by the ClearML experiment manager.
+
+If you want to change the `project_name` or `task_name`, use the `--project` and `--name` arguments of the `train.py` script, by default the project will be called `YOLOv5` and the task `Training`.
+PLEASE NOTE: ClearML uses `/` as a delimter for subprojects, so be careful when using `/` in your project name!
```bash
python train.py --img 640 --batch 16 --epochs 3 --data coco128.yaml --weights yolov5s.pt --cache
```
+or with custom project and task name:
+```bash
+python train.py --project my_project --name my_training --img 640 --batch 16 --epochs 3 --data coco128.yaml --weights yolov5s.pt --cache
+```
+
This will capture:
- Source code + uncommitted changes
- Installed packages
diff --git a/utils/loggers/clearml/clearml_utils.py b/utils/loggers/clearml/clearml_utils.py
index eb1c12c..3457727 100644
--- a/utils/loggers/clearml/clearml_utils.py
+++ b/utils/loggers/clearml/clearml_utils.py
@@ -85,10 +85,11 @@ class ClearmlLogger:
self.data_dict = None
if self.clearml:
self.task = Task.init(
- project_name='YOLOv5',
- task_name='training',
+ project_name=opt.project if opt.project != 'runs/train' else 'YOLOv5',
+ task_name=opt.name if opt.name != 'exp' else 'Training',
tags=['YOLOv5'],
output_uri=True,
+ reuse_last_task_id=opt.exist_ok,
auto_connect_frameworks={'pytorch': False}
# We disconnect pytorch auto-detection, because we added manual model save points in the code
)
@@ -96,6 +97,12 @@ class ClearmlLogger:
# Only the hyperparameters coming from the yaml config file
# will have to be added manually!
self.task.connect(hyp, name='Hyperparameters')
+ self.task.connect(opt, name='Args')
+
+ # Make sure the code is easily remotely runnable by setting the docker image to use by the remote agent
+ self.task.set_base_docker("ultralytics/yolov5:latest",
+ docker_arguments='--ipc=host -e="CLEARML_AGENT_SKIP_PYTHON_ENV_INSTALL=1"',
+ docker_setup_bash_script='pip install clearml')
# Get ClearML Dataset Version if requested
if opt.data.startswith('clearml://'):
diff --git a/utils/loggers/comet/README.md b/utils/loggers/comet/README.md
index 3a51cb9..8a361e2 100644
--- a/utils/loggers/comet/README.md
+++ b/utils/loggers/comet/README.md
@@ -2,13 +2,13 @@
# YOLOv5 with Comet
-This guide will cover how to use YOLOv5 with [Comet](https://bit.ly/yolov5-readme-comet)
+This guide will cover how to use YOLOv5 with [Comet](https://bit.ly/yolov5-readme-comet2)
# About Comet
Comet builds tools that help data scientists, engineers, and team leaders accelerate and optimize machine learning and deep learning models.
-Track and visualize model metrics in real time, save your hyperparameters, datasets, and model checkpoints, and visualize your model predictions with [Comet Custom Panels](https://bit.ly/yolov5-colab-comet-panels)!
+Track and visualize model metrics in real time, save your hyperparameters, datasets, and model checkpoints, and visualize your model predictions with [Comet Custom Panels](https://www.comet.com/docs/v2/guides/comet-dashboard/code-panels/about-panels/?utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=github)!
Comet makes sure you never lose track of your work and makes it easy to share results and collaborate across teams of all sizes!
# Getting Started
@@ -51,10 +51,10 @@ python train.py --img 640 --batch 16 --epochs 5 --data coco128.yaml --weights yo
That's it! Comet will automatically log your hyperparameters, command line arguments, training and valiation metrics. You can visualize and analyze your runs in the Comet UI
- +
+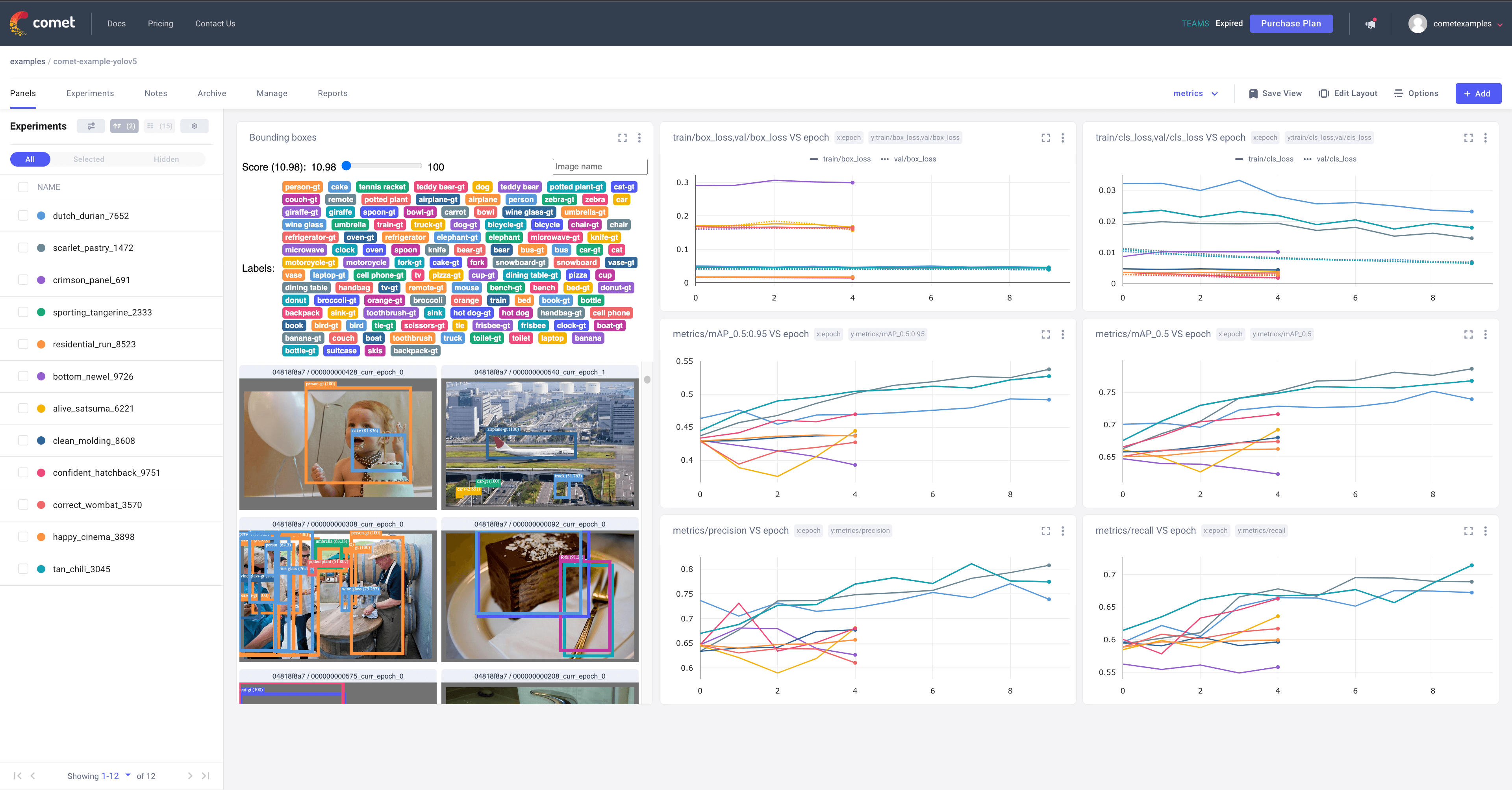 # Try out an Example!
-Check out an example of a [completed run here](https://www.comet.com/examples/comet-example-yolov5/a0e29e0e9b984e4a822db2a62d0cb357?experiment-tab=chart&showOutliers=true&smoothing=0&transformY=smoothing&xAxis=step&ref=yolov5&utm_source=yolov5&utm_medium=affilliate&utm_campaign=yolov5_comet_integration)
+Check out an example of a [completed run here](https://www.comet.com/examples/comet-example-yolov5/a0e29e0e9b984e4a822db2a62d0cb357?experiment-tab=chart&showOutliers=true&smoothing=0&transformY=smoothing&xAxis=step&utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=github)
Or better yet, try it out yourself in this Colab Notebook
@@ -119,7 +119,7 @@ You can control the frequency of logged predictions and the associated images by
**Note:** The YOLOv5 validation dataloader will default to a batch size of 32, so you will have to set the logging frequency accordingly.
-Here is an [example project using the Panel](https://www.comet.com/examples/comet-example-yolov5?shareable=YcwMiJaZSXfcEXpGOHDD12vA1&ref=yolov5&utm_source=yolov5&utm_medium=affilliate&utm_campaign=yolov5_comet_integration)
+Here is an [example project using the Panel](https://www.comet.com/examples/comet-example-yolov5?shareable=YcwMiJaZSXfcEXpGOHDD12vA1&utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=github)
```shell
@@ -161,7 +161,7 @@ env COMET_LOG_PER_CLASS_METRICS=true python train.py \
## Uploading a Dataset to Comet Artifacts
-If you would like to store your data using [Comet Artifacts](https://www.comet.com/docs/v2/guides/data-management/using-artifacts/#learn-more?ref=yolov5&utm_source=yolov5&utm_medium=affilliate&utm_campaign=yolov5_comet_integration), you can do so using the `upload_dataset` flag.
+If you would like to store your data using [Comet Artifacts](https://www.comet.com/docs/v2/guides/data-management/using-artifacts/#learn-more?utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=github), you can do so using the `upload_dataset` flag.
The dataset be organized in the way described in the [YOLOv5 documentation](https://docs.ultralytics.com/tutorials/train-custom-datasets/#3-organize-directories). The dataset config `yaml` file must follow the same format as that of the `coco128.yaml` file.
@@ -251,6 +251,6 @@ comet optimizer -j utils/loggers/comet/hpo.py \
### Visualizing Results
-Comet provides a number of ways to visualize the results of your sweep. Take a look at a [project with a completed sweep here](https://www.comet.com/examples/comet-example-yolov5/view/PrlArHGuuhDTKC1UuBmTtOSXD/panels?ref=yolov5&utm_source=yolov5&utm_medium=affilliate&utm_campaign=yolov5_comet_integration)
+Comet provides a number of ways to visualize the results of your sweep. Take a look at a [project with a completed sweep here](https://www.comet.com/examples/comet-example-yolov5/view/PrlArHGuuhDTKC1UuBmTtOSXD/panels?utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=github)
# Try out an Example!
-Check out an example of a [completed run here](https://www.comet.com/examples/comet-example-yolov5/a0e29e0e9b984e4a822db2a62d0cb357?experiment-tab=chart&showOutliers=true&smoothing=0&transformY=smoothing&xAxis=step&ref=yolov5&utm_source=yolov5&utm_medium=affilliate&utm_campaign=yolov5_comet_integration)
+Check out an example of a [completed run here](https://www.comet.com/examples/comet-example-yolov5/a0e29e0e9b984e4a822db2a62d0cb357?experiment-tab=chart&showOutliers=true&smoothing=0&transformY=smoothing&xAxis=step&utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=github)
Or better yet, try it out yourself in this Colab Notebook
@@ -119,7 +119,7 @@ You can control the frequency of logged predictions and the associated images by
**Note:** The YOLOv5 validation dataloader will default to a batch size of 32, so you will have to set the logging frequency accordingly.
-Here is an [example project using the Panel](https://www.comet.com/examples/comet-example-yolov5?shareable=YcwMiJaZSXfcEXpGOHDD12vA1&ref=yolov5&utm_source=yolov5&utm_medium=affilliate&utm_campaign=yolov5_comet_integration)
+Here is an [example project using the Panel](https://www.comet.com/examples/comet-example-yolov5?shareable=YcwMiJaZSXfcEXpGOHDD12vA1&utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=github)
```shell
@@ -161,7 +161,7 @@ env COMET_LOG_PER_CLASS_METRICS=true python train.py \
## Uploading a Dataset to Comet Artifacts
-If you would like to store your data using [Comet Artifacts](https://www.comet.com/docs/v2/guides/data-management/using-artifacts/#learn-more?ref=yolov5&utm_source=yolov5&utm_medium=affilliate&utm_campaign=yolov5_comet_integration), you can do so using the `upload_dataset` flag.
+If you would like to store your data using [Comet Artifacts](https://www.comet.com/docs/v2/guides/data-management/using-artifacts/#learn-more?utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=github), you can do so using the `upload_dataset` flag.
The dataset be organized in the way described in the [YOLOv5 documentation](https://docs.ultralytics.com/tutorials/train-custom-datasets/#3-organize-directories). The dataset config `yaml` file must follow the same format as that of the `coco128.yaml` file.
@@ -251,6 +251,6 @@ comet optimizer -j utils/loggers/comet/hpo.py \
### Visualizing Results
-Comet provides a number of ways to visualize the results of your sweep. Take a look at a [project with a completed sweep here](https://www.comet.com/examples/comet-example-yolov5/view/PrlArHGuuhDTKC1UuBmTtOSXD/panels?ref=yolov5&utm_source=yolov5&utm_medium=affilliate&utm_campaign=yolov5_comet_integration)
+Comet provides a number of ways to visualize the results of your sweep. Take a look at a [project with a completed sweep here](https://www.comet.com/examples/comet-example-yolov5/view/PrlArHGuuhDTKC1UuBmTtOSXD/panels?utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=github)
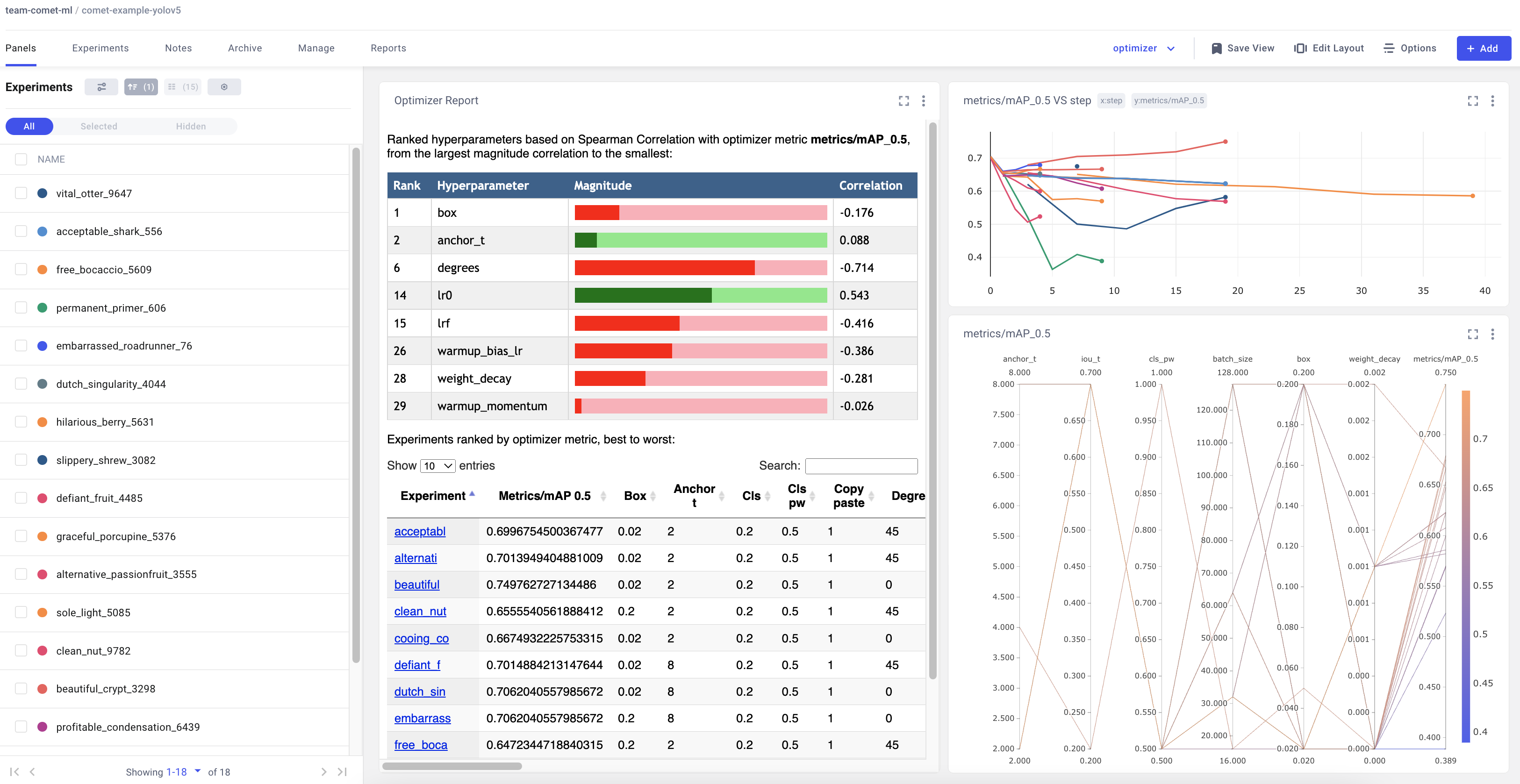 diff --git a/utils/loggers/comet/__init__.py b/utils/loggers/comet/__init__.py
index ba5cecc..b0318f8 100644
--- a/utils/loggers/comet/__init__.py
+++ b/utils/loggers/comet/__init__.py
@@ -353,7 +353,14 @@ class CometLogger:
metadata = logged_artifact.metadata
data_dict = metadata.copy()
data_dict["path"] = artifact_save_dir
- data_dict["names"] = {int(k): v for k, v in metadata.get("names").items()}
+
+ metadata_names = metadata.get("names")
+ if type(metadata_names) == dict:
+ data_dict["names"] = {int(k): v for k, v in metadata.get("names").items()}
+ elif type(metadata_names) == list:
+ data_dict["names"] = {int(k): v for k, v in zip(range(len(metadata_names)), metadata_names)}
+ else:
+ raise "Invalid 'names' field in dataset yaml file. Please use a list or dictionary"
data_dict = self.update_data_paths(data_dict)
return data_dict
diff --git a/utils/loggers/wandb/wandb_utils.py b/utils/loggers/wandb/wandb_utils.py
index e850d2a..238f4ed 100644
--- a/utils/loggers/wandb/wandb_utils.py
+++ b/utils/loggers/wandb/wandb_utils.py
@@ -132,6 +132,11 @@ class WandbLogger():
job_type (str) -- To set the job_type for this run
"""
+ # Temporary-fix
+ if opt.upload_dataset:
+ opt.upload_dataset = False
+ # LOGGER.info("Uploading Dataset functionality is not being supported temporarily due to a bug.")
+
# Pre-training routine --
self.job_type = job_type
self.wandb, self.wandb_run = wandb, None if not wandb else wandb.run
diff --git a/utils/metrics.py b/utils/metrics.py
index ed611d7..c01f823 100644
--- a/utils/metrics.py
+++ b/utils/metrics.py
@@ -177,16 +177,13 @@ class ConfusionMatrix:
if not any(m1 == i):
self.matrix[dc, self.nc] += 1 # predicted background
- def matrix(self):
- return self.matrix
-
def tp_fp(self):
tp = self.matrix.diagonal() # true positives
fp = self.matrix.sum(1) - tp # false positives
# fn = self.matrix.sum(0) - tp # false negatives (missed detections)
return tp[:-1], fp[:-1] # remove background class
- @TryExcept('WARNING ⚠️ ConfusionMatrix plot failure: ')
+ @TryExcept('WARNING ⚠️ ConfusionMatrix plot failure')
def plot(self, normalize=True, save_dir='', names=()):
import seaborn as sn
@@ -227,19 +224,19 @@ def bbox_iou(box1, box2, xywh=True, GIoU=False, DIoU=False, CIoU=False, eps=1e-7
# Get the coordinates of bounding boxes
if xywh: # transform from xywh to xyxy
- (x1, y1, w1, h1), (x2, y2, w2, h2) = box1.chunk(4, 1), box2.chunk(4, 1)
+ (x1, y1, w1, h1), (x2, y2, w2, h2) = box1.chunk(4, -1), box2.chunk(4, -1)
w1_, h1_, w2_, h2_ = w1 / 2, h1 / 2, w2 / 2, h2 / 2
b1_x1, b1_x2, b1_y1, b1_y2 = x1 - w1_, x1 + w1_, y1 - h1_, y1 + h1_
b2_x1, b2_x2, b2_y1, b2_y2 = x2 - w2_, x2 + w2_, y2 - h2_, y2 + h2_
else: # x1, y1, x2, y2 = box1
- b1_x1, b1_y1, b1_x2, b1_y2 = box1.chunk(4, 1)
- b2_x1, b2_y1, b2_x2, b2_y2 = box2.chunk(4, 1)
- w1, h1 = b1_x2 - b1_x1, b1_y2 - b1_y1
- w2, h2 = b2_x2 - b2_x1, b2_y2 - b2_y1
+ b1_x1, b1_y1, b1_x2, b1_y2 = box1.chunk(4, -1)
+ b2_x1, b2_y1, b2_x2, b2_y2 = box2.chunk(4, -1)
+ w1, h1 = b1_x2 - b1_x1, (b1_y2 - b1_y1).clamp(eps)
+ w2, h2 = b2_x2 - b2_x1, (b2_y2 - b2_y1).clamp(eps)
# Intersection area
- inter = (torch.min(b1_x2, b2_x2) - torch.max(b1_x1, b2_x1)).clamp(0) * \
- (torch.min(b1_y2, b2_y2) - torch.max(b1_y1, b2_y1)).clamp(0)
+ inter = (b1_x2.minimum(b2_x2) - b1_x1.maximum(b2_x1)).clamp(0) * \
+ (b1_y2.minimum(b2_y2) - b1_y1.maximum(b2_y1)).clamp(0)
# Union Area
union = w1 * h1 + w2 * h2 - inter + eps
@@ -247,13 +244,13 @@ def bbox_iou(box1, box2, xywh=True, GIoU=False, DIoU=False, CIoU=False, eps=1e-7
# IoU
iou = inter / union
if CIoU or DIoU or GIoU:
- cw = torch.max(b1_x2, b2_x2) - torch.min(b1_x1, b2_x1) # convex (smallest enclosing box) width
- ch = torch.max(b1_y2, b2_y2) - torch.min(b1_y1, b2_y1) # convex height
+ cw = b1_x2.maximum(b2_x2) - b1_x1.minimum(b2_x1) # convex (smallest enclosing box) width
+ ch = b1_y2.maximum(b2_y2) - b1_y1.minimum(b2_y1) # convex height
if CIoU or DIoU: # Distance or Complete IoU https://arxiv.org/abs/1911.08287v1
c2 = cw ** 2 + ch ** 2 + eps # convex diagonal squared
rho2 = ((b2_x1 + b2_x2 - b1_x1 - b1_x2) ** 2 + (b2_y1 + b2_y2 - b1_y1 - b1_y2) ** 2) / 4 # center dist ** 2
if CIoU: # https://github.com/Zzh-tju/DIoU-SSD-pytorch/blob/master/utils/box/box_utils.py#L47
- v = (4 / math.pi ** 2) * torch.pow(torch.atan(w2 / (h2 + eps)) - torch.atan(w1 / (h1 + eps)), 2)
+ v = (4 / math.pi ** 2) * (torch.atan(w2 / h2) - torch.atan(w1 / h1)).pow(2)
with torch.no_grad():
alpha = v / (v - iou + (1 + eps))
return iou - (rho2 / c2 + v * alpha) # CIoU
@@ -263,11 +260,6 @@ def bbox_iou(box1, box2, xywh=True, GIoU=False, DIoU=False, CIoU=False, eps=1e-7
return iou # IoU
-def box_area(box):
- # box = xyxy(4,n)
- return (box[2] - box[0]) * (box[3] - box[1])
-
-
def box_iou(box1, box2, eps=1e-7):
# https://github.com/pytorch/vision/blob/master/torchvision/ops/boxes.py
"""
@@ -282,11 +274,11 @@ def box_iou(box1, box2, eps=1e-7):
"""
# inter(N,M) = (rb(N,M,2) - lt(N,M,2)).clamp(0).prod(2)
- (a1, a2), (b1, b2) = box1[:, None].chunk(2, 2), box2.chunk(2, 1)
+ (a1, a2), (b1, b2) = box1.unsqueeze(1).chunk(2, 2), box2.unsqueeze(0).chunk(2, 2)
inter = (torch.min(a2, b2) - torch.max(a1, b1)).clamp(0).prod(2)
# IoU = inter / (area1 + area2 - inter)
- return inter / (box_area(box1.T)[:, None] + box_area(box2.T) - inter + eps)
+ return inter / ((a2 - a1).prod(2) + (b2 - b1).prod(2) - inter + eps)
def bbox_ioa(box1, box2, eps=1e-7):
diff --git a/utils/plots.py b/utils/plots.py
index 36df271..d2f232d 100644
--- a/utils/plots.py
+++ b/utils/plots.py
@@ -114,7 +114,7 @@ class Annotator:
thickness=tf,
lineType=cv2.LINE_AA)
- def masks(self, masks, colors, im_gpu=None, alpha=0.5):
+ def masks(self, masks, colors, im_gpu, alpha=0.5, retina_masks=False):
"""Plot masks at once.
Args:
masks (tensor): predicted masks on cuda, shape: [n, h, w]
@@ -125,37 +125,21 @@ class Annotator:
if self.pil:
# convert to numpy first
self.im = np.asarray(self.im).copy()
- if im_gpu is None:
- # Add multiple masks of shape(h,w,n) with colors list([r,g,b], [r,g,b], ...)
- if len(masks) == 0:
- return
- if isinstance(masks, torch.Tensor):
- masks = torch.as_tensor(masks, dtype=torch.uint8)
- masks = masks.permute(1, 2, 0).contiguous()
- masks = masks.cpu().numpy()
- # masks = np.ascontiguousarray(masks.transpose(1, 2, 0))
- masks = scale_image(masks.shape[:2], masks, self.im.shape)
- masks = np.asarray(masks, dtype=np.float32)
- colors = np.asarray(colors, dtype=np.float32) # shape(n,3)
- s = masks.sum(2, keepdims=True).clip(0, 1) # add all masks together
- masks = (masks @ colors).clip(0, 255) # (h,w,n) @ (n,3) = (h,w,3)
- self.im[:] = masks * alpha + self.im * (1 - s * alpha)
- else:
- if len(masks) == 0:
- self.im[:] = im_gpu.permute(1, 2, 0).contiguous().cpu().numpy() * 255
- colors = torch.tensor(colors, device=im_gpu.device, dtype=torch.float32) / 255.0
- colors = colors[:, None, None] # shape(n,1,1,3)
- masks = masks.unsqueeze(3) # shape(n,h,w,1)
- masks_color = masks * (colors * alpha) # shape(n,h,w,3)
+ if len(masks) == 0:
+ self.im[:] = im_gpu.permute(1, 2, 0).contiguous().cpu().numpy() * 255
+ colors = torch.tensor(colors, device=im_gpu.device, dtype=torch.float32) / 255.0
+ colors = colors[:, None, None] # shape(n,1,1,3)
+ masks = masks.unsqueeze(3) # shape(n,h,w,1)
+ masks_color = masks * (colors * alpha) # shape(n,h,w,3)
- inv_alph_masks = (1 - masks * alpha).cumprod(0) # shape(n,h,w,1)
- mcs = (masks_color * inv_alph_masks).sum(0) * 2 # mask color summand shape(n,h,w,3)
+ inv_alph_masks = (1 - masks * alpha).cumprod(0) # shape(n,h,w,1)
+ mcs = (masks_color * inv_alph_masks).sum(0) * 2 # mask color summand shape(n,h,w,3)
- im_gpu = im_gpu.flip(dims=[0]) # flip channel
- im_gpu = im_gpu.permute(1, 2, 0).contiguous() # shape(h,w,3)
- im_gpu = im_gpu * inv_alph_masks[-1] + mcs
- im_mask = (im_gpu * 255).byte().cpu().numpy()
- self.im[:] = scale_image(im_gpu.shape, im_mask, self.im.shape)
+ im_gpu = im_gpu.flip(dims=[0]) # flip channel
+ im_gpu = im_gpu.permute(1, 2, 0).contiguous() # shape(h,w,3)
+ im_gpu = im_gpu * inv_alph_masks[-1] + mcs
+ im_mask = (im_gpu * 255).byte().cpu().numpy()
+ self.im[:] = im_mask if retina_masks else scale_image(im_gpu.shape, im_mask, self.im.shape)
if self.pil:
# convert im back to PIL and update draw
self.fromarray(self.im)
diff --git a/utils/segment/dataloaders.py b/utils/segment/dataloaders.py
index a63d6ec..d66b361 100644
--- a/utils/segment/dataloaders.py
+++ b/utils/segment/dataloaders.py
@@ -37,7 +37,8 @@ def create_dataloader(path,
prefix='',
shuffle=False,
mask_downsample_ratio=1,
- overlap_mask=False):
+ overlap_mask=False,
+ seed=0):
if rect and shuffle:
LOGGER.warning('WARNING ⚠️ --rect is incompatible with DataLoader shuffle, setting shuffle=False')
shuffle = False
@@ -64,7 +65,7 @@ def create_dataloader(path,
sampler = None if rank == -1 else distributed.DistributedSampler(dataset, shuffle=shuffle)
loader = DataLoader if image_weights else InfiniteDataLoader # only DataLoader allows for attribute updates
generator = torch.Generator()
- generator.manual_seed(6148914691236517205 + RANK)
+ generator.manual_seed(6148914691236517205 + seed + RANK)
return loader(
dataset,
batch_size=batch_size,
@@ -93,12 +94,13 @@ class LoadImagesAndLabelsAndMasks(LoadImagesAndLabels): # for training/testing
single_cls=False,
stride=32,
pad=0,
+ min_items=0,
prefix="",
downsample_ratio=1,
overlap=False,
):
super().__init__(path, img_size, batch_size, augment, hyp, rect, image_weights, cache_images, single_cls,
- stride, pad, prefix)
+ stride, pad, min_items, prefix)
self.downsample_ratio = downsample_ratio
self.overlap = overlap
diff --git a/utils/segment/general.py b/utils/segment/general.py
index 655123b..9da8945 100644
--- a/utils/segment/general.py
+++ b/utils/segment/general.py
@@ -25,10 +25,10 @@ def crop_mask(masks, boxes):
def process_mask_upsample(protos, masks_in, bboxes, shape):
"""
Crop after upsample.
- proto_out: [mask_dim, mask_h, mask_w]
- out_masks: [n, mask_dim], n is number of masks after nms
+ protos: [mask_dim, mask_h, mask_w]
+ masks_in: [n, mask_dim], n is number of masks after nms
bboxes: [n, 4], n is number of masks after nms
- shape:input_image_size, (h, w)
+ shape: input_image_size, (h, w)
return: h, w, n
"""
@@ -67,6 +67,29 @@ def process_mask(protos, masks_in, bboxes, shape, upsample=False):
return masks.gt_(0.5)
+def process_mask_native(protos, masks_in, bboxes, shape):
+ """
+ Crop after upsample.
+ protos: [mask_dim, mask_h, mask_w]
+ masks_in: [n, mask_dim], n is number of masks after nms
+ bboxes: [n, 4], n is number of masks after nms
+ shape: input_image_size, (h, w)
+
+ return: h, w, n
+ """
+ c, mh, mw = protos.shape # CHW
+ masks = (masks_in @ protos.float().view(c, -1)).sigmoid().view(-1, mh, mw)
+ gain = min(mh / shape[0], mw / shape[1]) # gain = old / new
+ pad = (mw - shape[1] * gain) / 2, (mh - shape[0] * gain) / 2 # wh padding
+ top, left = int(pad[1]), int(pad[0]) # y, x
+ bottom, right = int(mh - pad[1]), int(mw - pad[0])
+ masks = masks[:, top:bottom, left:right]
+
+ masks = F.interpolate(masks[None], shape, mode='bilinear', align_corners=False)[0] # CHW
+ masks = crop_mask(masks, bboxes) # CHW
+ return masks.gt_(0.5)
+
+
def scale_image(im1_shape, masks, im0_shape, ratio_pad=None):
"""
img1_shape: model input shape, [h, w]
@@ -124,11 +147,14 @@ def masks_iou(mask1, mask2, eps=1e-7):
def masks2segments(masks, strategy='largest'):
# Convert masks(n,160,160) into segments(n,xy)
segments = []
- for x in masks.int().numpy().astype('uint8'):
+ for x in masks.int().cpu().numpy().astype('uint8'):
c = cv2.findContours(x, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)[0]
- if strategy == 'concat': # concatenate all segments
- c = np.concatenate([x.reshape(-1, 2) for x in c])
- elif strategy == 'largest': # select largest segment
- c = np.array(c[np.array([len(x) for x in c]).argmax()]).reshape(-1, 2)
+ if c:
+ if strategy == 'concat': # concatenate all segments
+ c = np.concatenate([x.reshape(-1, 2) for x in c])
+ elif strategy == 'largest': # select largest segment
+ c = np.array(c[np.array([len(x) for x in c]).argmax()]).reshape(-1, 2)
+ else:
+ c = np.zeros((0, 2)) # no segments found
segments.append(c.astype('float32'))
return segments
diff --git a/utils/torch_utils.py b/utils/torch_utils.py
index 9f257d0..77549b0 100644
--- a/utils/torch_utils.py
+++ b/utils/torch_utils.py
@@ -32,6 +32,7 @@ except ImportError:
# Suppress PyTorch warnings
warnings.filterwarnings('ignore', message='User provided device_type of \'cuda\', but CUDA is not available. Disabling')
+warnings.filterwarnings('ignore', category=UserWarning)
def smart_inference_mode(torch_1_9=check_version(torch.__version__, '1.9.0')):
@@ -81,7 +82,7 @@ def reshape_classifier_output(model, n=1000):
elif nn.Conv2d in types:
i = types.index(nn.Conv2d) # nn.Conv2d index
if m[i].out_channels != n:
- m[i] = nn.Conv2d(m[i].in_channels, n, m[i].kernel_size, m[i].stride, bias=m[i].bias)
+ m[i] = nn.Conv2d(m[i].in_channels, n, m[i].kernel_size, m[i].stride, bias=m[i].bias is not None)
@contextmanager
@@ -319,12 +320,13 @@ def smart_optimizer(model, name='Adam', lr=0.001, momentum=0.9, decay=1e-5):
g = [], [], [] # optimizer parameter groups
bn = tuple(v for k, v in nn.__dict__.items() if 'Norm' in k) # normalization layers, i.e. BatchNorm2d()
for v in model.modules():
- if hasattr(v, 'bias') and isinstance(v.bias, nn.Parameter): # bias (no decay)
- g[2].append(v.bias)
- if isinstance(v, bn): # weight (no decay)
- g[1].append(v.weight)
- elif hasattr(v, 'weight') and isinstance(v.weight, nn.Parameter): # weight (with decay)
- g[0].append(v.weight)
+ for p_name, p in v.named_parameters(recurse=0):
+ if p_name == 'bias': # bias (no decay)
+ g[2].append(p)
+ elif p_name == 'weight' and isinstance(v, bn): # weight (no decay)
+ g[1].append(p)
+ else:
+ g[0].append(p) # weight (with decay)
if name == 'Adam':
optimizer = torch.optim.Adam(g[2], lr=lr, betas=(momentum, 0.999)) # adjust beta1 to momentum
diff --git a/yolov5s320Half.engine b/yolov5s320Half.engine
index a783c83..b42881e 100644
Binary files a/yolov5s320Half.engine and b/yolov5s320Half.engine differ
diff --git a/utils/loggers/comet/__init__.py b/utils/loggers/comet/__init__.py
index ba5cecc..b0318f8 100644
--- a/utils/loggers/comet/__init__.py
+++ b/utils/loggers/comet/__init__.py
@@ -353,7 +353,14 @@ class CometLogger:
metadata = logged_artifact.metadata
data_dict = metadata.copy()
data_dict["path"] = artifact_save_dir
- data_dict["names"] = {int(k): v for k, v in metadata.get("names").items()}
+
+ metadata_names = metadata.get("names")
+ if type(metadata_names) == dict:
+ data_dict["names"] = {int(k): v for k, v in metadata.get("names").items()}
+ elif type(metadata_names) == list:
+ data_dict["names"] = {int(k): v for k, v in zip(range(len(metadata_names)), metadata_names)}
+ else:
+ raise "Invalid 'names' field in dataset yaml file. Please use a list or dictionary"
data_dict = self.update_data_paths(data_dict)
return data_dict
diff --git a/utils/loggers/wandb/wandb_utils.py b/utils/loggers/wandb/wandb_utils.py
index e850d2a..238f4ed 100644
--- a/utils/loggers/wandb/wandb_utils.py
+++ b/utils/loggers/wandb/wandb_utils.py
@@ -132,6 +132,11 @@ class WandbLogger():
job_type (str) -- To set the job_type for this run
"""
+ # Temporary-fix
+ if opt.upload_dataset:
+ opt.upload_dataset = False
+ # LOGGER.info("Uploading Dataset functionality is not being supported temporarily due to a bug.")
+
# Pre-training routine --
self.job_type = job_type
self.wandb, self.wandb_run = wandb, None if not wandb else wandb.run
diff --git a/utils/metrics.py b/utils/metrics.py
index ed611d7..c01f823 100644
--- a/utils/metrics.py
+++ b/utils/metrics.py
@@ -177,16 +177,13 @@ class ConfusionMatrix:
if not any(m1 == i):
self.matrix[dc, self.nc] += 1 # predicted background
- def matrix(self):
- return self.matrix
-
def tp_fp(self):
tp = self.matrix.diagonal() # true positives
fp = self.matrix.sum(1) - tp # false positives
# fn = self.matrix.sum(0) - tp # false negatives (missed detections)
return tp[:-1], fp[:-1] # remove background class
- @TryExcept('WARNING ⚠️ ConfusionMatrix plot failure: ')
+ @TryExcept('WARNING ⚠️ ConfusionMatrix plot failure')
def plot(self, normalize=True, save_dir='', names=()):
import seaborn as sn
@@ -227,19 +224,19 @@ def bbox_iou(box1, box2, xywh=True, GIoU=False, DIoU=False, CIoU=False, eps=1e-7
# Get the coordinates of bounding boxes
if xywh: # transform from xywh to xyxy
- (x1, y1, w1, h1), (x2, y2, w2, h2) = box1.chunk(4, 1), box2.chunk(4, 1)
+ (x1, y1, w1, h1), (x2, y2, w2, h2) = box1.chunk(4, -1), box2.chunk(4, -1)
w1_, h1_, w2_, h2_ = w1 / 2, h1 / 2, w2 / 2, h2 / 2
b1_x1, b1_x2, b1_y1, b1_y2 = x1 - w1_, x1 + w1_, y1 - h1_, y1 + h1_
b2_x1, b2_x2, b2_y1, b2_y2 = x2 - w2_, x2 + w2_, y2 - h2_, y2 + h2_
else: # x1, y1, x2, y2 = box1
- b1_x1, b1_y1, b1_x2, b1_y2 = box1.chunk(4, 1)
- b2_x1, b2_y1, b2_x2, b2_y2 = box2.chunk(4, 1)
- w1, h1 = b1_x2 - b1_x1, b1_y2 - b1_y1
- w2, h2 = b2_x2 - b2_x1, b2_y2 - b2_y1
+ b1_x1, b1_y1, b1_x2, b1_y2 = box1.chunk(4, -1)
+ b2_x1, b2_y1, b2_x2, b2_y2 = box2.chunk(4, -1)
+ w1, h1 = b1_x2 - b1_x1, (b1_y2 - b1_y1).clamp(eps)
+ w2, h2 = b2_x2 - b2_x1, (b2_y2 - b2_y1).clamp(eps)
# Intersection area
- inter = (torch.min(b1_x2, b2_x2) - torch.max(b1_x1, b2_x1)).clamp(0) * \
- (torch.min(b1_y2, b2_y2) - torch.max(b1_y1, b2_y1)).clamp(0)
+ inter = (b1_x2.minimum(b2_x2) - b1_x1.maximum(b2_x1)).clamp(0) * \
+ (b1_y2.minimum(b2_y2) - b1_y1.maximum(b2_y1)).clamp(0)
# Union Area
union = w1 * h1 + w2 * h2 - inter + eps
@@ -247,13 +244,13 @@ def bbox_iou(box1, box2, xywh=True, GIoU=False, DIoU=False, CIoU=False, eps=1e-7
# IoU
iou = inter / union
if CIoU or DIoU or GIoU:
- cw = torch.max(b1_x2, b2_x2) - torch.min(b1_x1, b2_x1) # convex (smallest enclosing box) width
- ch = torch.max(b1_y2, b2_y2) - torch.min(b1_y1, b2_y1) # convex height
+ cw = b1_x2.maximum(b2_x2) - b1_x1.minimum(b2_x1) # convex (smallest enclosing box) width
+ ch = b1_y2.maximum(b2_y2) - b1_y1.minimum(b2_y1) # convex height
if CIoU or DIoU: # Distance or Complete IoU https://arxiv.org/abs/1911.08287v1
c2 = cw ** 2 + ch ** 2 + eps # convex diagonal squared
rho2 = ((b2_x1 + b2_x2 - b1_x1 - b1_x2) ** 2 + (b2_y1 + b2_y2 - b1_y1 - b1_y2) ** 2) / 4 # center dist ** 2
if CIoU: # https://github.com/Zzh-tju/DIoU-SSD-pytorch/blob/master/utils/box/box_utils.py#L47
- v = (4 / math.pi ** 2) * torch.pow(torch.atan(w2 / (h2 + eps)) - torch.atan(w1 / (h1 + eps)), 2)
+ v = (4 / math.pi ** 2) * (torch.atan(w2 / h2) - torch.atan(w1 / h1)).pow(2)
with torch.no_grad():
alpha = v / (v - iou + (1 + eps))
return iou - (rho2 / c2 + v * alpha) # CIoU
@@ -263,11 +260,6 @@ def bbox_iou(box1, box2, xywh=True, GIoU=False, DIoU=False, CIoU=False, eps=1e-7
return iou # IoU
-def box_area(box):
- # box = xyxy(4,n)
- return (box[2] - box[0]) * (box[3] - box[1])
-
-
def box_iou(box1, box2, eps=1e-7):
# https://github.com/pytorch/vision/blob/master/torchvision/ops/boxes.py
"""
@@ -282,11 +274,11 @@ def box_iou(box1, box2, eps=1e-7):
"""
# inter(N,M) = (rb(N,M,2) - lt(N,M,2)).clamp(0).prod(2)
- (a1, a2), (b1, b2) = box1[:, None].chunk(2, 2), box2.chunk(2, 1)
+ (a1, a2), (b1, b2) = box1.unsqueeze(1).chunk(2, 2), box2.unsqueeze(0).chunk(2, 2)
inter = (torch.min(a2, b2) - torch.max(a1, b1)).clamp(0).prod(2)
# IoU = inter / (area1 + area2 - inter)
- return inter / (box_area(box1.T)[:, None] + box_area(box2.T) - inter + eps)
+ return inter / ((a2 - a1).prod(2) + (b2 - b1).prod(2) - inter + eps)
def bbox_ioa(box1, box2, eps=1e-7):
diff --git a/utils/plots.py b/utils/plots.py
index 36df271..d2f232d 100644
--- a/utils/plots.py
+++ b/utils/plots.py
@@ -114,7 +114,7 @@ class Annotator:
thickness=tf,
lineType=cv2.LINE_AA)
- def masks(self, masks, colors, im_gpu=None, alpha=0.5):
+ def masks(self, masks, colors, im_gpu, alpha=0.5, retina_masks=False):
"""Plot masks at once.
Args:
masks (tensor): predicted masks on cuda, shape: [n, h, w]
@@ -125,37 +125,21 @@ class Annotator:
if self.pil:
# convert to numpy first
self.im = np.asarray(self.im).copy()
- if im_gpu is None:
- # Add multiple masks of shape(h,w,n) with colors list([r,g,b], [r,g,b], ...)
- if len(masks) == 0:
- return
- if isinstance(masks, torch.Tensor):
- masks = torch.as_tensor(masks, dtype=torch.uint8)
- masks = masks.permute(1, 2, 0).contiguous()
- masks = masks.cpu().numpy()
- # masks = np.ascontiguousarray(masks.transpose(1, 2, 0))
- masks = scale_image(masks.shape[:2], masks, self.im.shape)
- masks = np.asarray(masks, dtype=np.float32)
- colors = np.asarray(colors, dtype=np.float32) # shape(n,3)
- s = masks.sum(2, keepdims=True).clip(0, 1) # add all masks together
- masks = (masks @ colors).clip(0, 255) # (h,w,n) @ (n,3) = (h,w,3)
- self.im[:] = masks * alpha + self.im * (1 - s * alpha)
- else:
- if len(masks) == 0:
- self.im[:] = im_gpu.permute(1, 2, 0).contiguous().cpu().numpy() * 255
- colors = torch.tensor(colors, device=im_gpu.device, dtype=torch.float32) / 255.0
- colors = colors[:, None, None] # shape(n,1,1,3)
- masks = masks.unsqueeze(3) # shape(n,h,w,1)
- masks_color = masks * (colors * alpha) # shape(n,h,w,3)
+ if len(masks) == 0:
+ self.im[:] = im_gpu.permute(1, 2, 0).contiguous().cpu().numpy() * 255
+ colors = torch.tensor(colors, device=im_gpu.device, dtype=torch.float32) / 255.0
+ colors = colors[:, None, None] # shape(n,1,1,3)
+ masks = masks.unsqueeze(3) # shape(n,h,w,1)
+ masks_color = masks * (colors * alpha) # shape(n,h,w,3)
- inv_alph_masks = (1 - masks * alpha).cumprod(0) # shape(n,h,w,1)
- mcs = (masks_color * inv_alph_masks).sum(0) * 2 # mask color summand shape(n,h,w,3)
+ inv_alph_masks = (1 - masks * alpha).cumprod(0) # shape(n,h,w,1)
+ mcs = (masks_color * inv_alph_masks).sum(0) * 2 # mask color summand shape(n,h,w,3)
- im_gpu = im_gpu.flip(dims=[0]) # flip channel
- im_gpu = im_gpu.permute(1, 2, 0).contiguous() # shape(h,w,3)
- im_gpu = im_gpu * inv_alph_masks[-1] + mcs
- im_mask = (im_gpu * 255).byte().cpu().numpy()
- self.im[:] = scale_image(im_gpu.shape, im_mask, self.im.shape)
+ im_gpu = im_gpu.flip(dims=[0]) # flip channel
+ im_gpu = im_gpu.permute(1, 2, 0).contiguous() # shape(h,w,3)
+ im_gpu = im_gpu * inv_alph_masks[-1] + mcs
+ im_mask = (im_gpu * 255).byte().cpu().numpy()
+ self.im[:] = im_mask if retina_masks else scale_image(im_gpu.shape, im_mask, self.im.shape)
if self.pil:
# convert im back to PIL and update draw
self.fromarray(self.im)
diff --git a/utils/segment/dataloaders.py b/utils/segment/dataloaders.py
index a63d6ec..d66b361 100644
--- a/utils/segment/dataloaders.py
+++ b/utils/segment/dataloaders.py
@@ -37,7 +37,8 @@ def create_dataloader(path,
prefix='',
shuffle=False,
mask_downsample_ratio=1,
- overlap_mask=False):
+ overlap_mask=False,
+ seed=0):
if rect and shuffle:
LOGGER.warning('WARNING ⚠️ --rect is incompatible with DataLoader shuffle, setting shuffle=False')
shuffle = False
@@ -64,7 +65,7 @@ def create_dataloader(path,
sampler = None if rank == -1 else distributed.DistributedSampler(dataset, shuffle=shuffle)
loader = DataLoader if image_weights else InfiniteDataLoader # only DataLoader allows for attribute updates
generator = torch.Generator()
- generator.manual_seed(6148914691236517205 + RANK)
+ generator.manual_seed(6148914691236517205 + seed + RANK)
return loader(
dataset,
batch_size=batch_size,
@@ -93,12 +94,13 @@ class LoadImagesAndLabelsAndMasks(LoadImagesAndLabels): # for training/testing
single_cls=False,
stride=32,
pad=0,
+ min_items=0,
prefix="",
downsample_ratio=1,
overlap=False,
):
super().__init__(path, img_size, batch_size, augment, hyp, rect, image_weights, cache_images, single_cls,
- stride, pad, prefix)
+ stride, pad, min_items, prefix)
self.downsample_ratio = downsample_ratio
self.overlap = overlap
diff --git a/utils/segment/general.py b/utils/segment/general.py
index 655123b..9da8945 100644
--- a/utils/segment/general.py
+++ b/utils/segment/general.py
@@ -25,10 +25,10 @@ def crop_mask(masks, boxes):
def process_mask_upsample(protos, masks_in, bboxes, shape):
"""
Crop after upsample.
- proto_out: [mask_dim, mask_h, mask_w]
- out_masks: [n, mask_dim], n is number of masks after nms
+ protos: [mask_dim, mask_h, mask_w]
+ masks_in: [n, mask_dim], n is number of masks after nms
bboxes: [n, 4], n is number of masks after nms
- shape:input_image_size, (h, w)
+ shape: input_image_size, (h, w)
return: h, w, n
"""
@@ -67,6 +67,29 @@ def process_mask(protos, masks_in, bboxes, shape, upsample=False):
return masks.gt_(0.5)
+def process_mask_native(protos, masks_in, bboxes, shape):
+ """
+ Crop after upsample.
+ protos: [mask_dim, mask_h, mask_w]
+ masks_in: [n, mask_dim], n is number of masks after nms
+ bboxes: [n, 4], n is number of masks after nms
+ shape: input_image_size, (h, w)
+
+ return: h, w, n
+ """
+ c, mh, mw = protos.shape # CHW
+ masks = (masks_in @ protos.float().view(c, -1)).sigmoid().view(-1, mh, mw)
+ gain = min(mh / shape[0], mw / shape[1]) # gain = old / new
+ pad = (mw - shape[1] * gain) / 2, (mh - shape[0] * gain) / 2 # wh padding
+ top, left = int(pad[1]), int(pad[0]) # y, x
+ bottom, right = int(mh - pad[1]), int(mw - pad[0])
+ masks = masks[:, top:bottom, left:right]
+
+ masks = F.interpolate(masks[None], shape, mode='bilinear', align_corners=False)[0] # CHW
+ masks = crop_mask(masks, bboxes) # CHW
+ return masks.gt_(0.5)
+
+
def scale_image(im1_shape, masks, im0_shape, ratio_pad=None):
"""
img1_shape: model input shape, [h, w]
@@ -124,11 +147,14 @@ def masks_iou(mask1, mask2, eps=1e-7):
def masks2segments(masks, strategy='largest'):
# Convert masks(n,160,160) into segments(n,xy)
segments = []
- for x in masks.int().numpy().astype('uint8'):
+ for x in masks.int().cpu().numpy().astype('uint8'):
c = cv2.findContours(x, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)[0]
- if strategy == 'concat': # concatenate all segments
- c = np.concatenate([x.reshape(-1, 2) for x in c])
- elif strategy == 'largest': # select largest segment
- c = np.array(c[np.array([len(x) for x in c]).argmax()]).reshape(-1, 2)
+ if c:
+ if strategy == 'concat': # concatenate all segments
+ c = np.concatenate([x.reshape(-1, 2) for x in c])
+ elif strategy == 'largest': # select largest segment
+ c = np.array(c[np.array([len(x) for x in c]).argmax()]).reshape(-1, 2)
+ else:
+ c = np.zeros((0, 2)) # no segments found
segments.append(c.astype('float32'))
return segments
diff --git a/utils/torch_utils.py b/utils/torch_utils.py
index 9f257d0..77549b0 100644
--- a/utils/torch_utils.py
+++ b/utils/torch_utils.py
@@ -32,6 +32,7 @@ except ImportError:
# Suppress PyTorch warnings
warnings.filterwarnings('ignore', message='User provided device_type of \'cuda\', but CUDA is not available. Disabling')
+warnings.filterwarnings('ignore', category=UserWarning)
def smart_inference_mode(torch_1_9=check_version(torch.__version__, '1.9.0')):
@@ -81,7 +82,7 @@ def reshape_classifier_output(model, n=1000):
elif nn.Conv2d in types:
i = types.index(nn.Conv2d) # nn.Conv2d index
if m[i].out_channels != n:
- m[i] = nn.Conv2d(m[i].in_channels, n, m[i].kernel_size, m[i].stride, bias=m[i].bias)
+ m[i] = nn.Conv2d(m[i].in_channels, n, m[i].kernel_size, m[i].stride, bias=m[i].bias is not None)
@contextmanager
@@ -319,12 +320,13 @@ def smart_optimizer(model, name='Adam', lr=0.001, momentum=0.9, decay=1e-5):
g = [], [], [] # optimizer parameter groups
bn = tuple(v for k, v in nn.__dict__.items() if 'Norm' in k) # normalization layers, i.e. BatchNorm2d()
for v in model.modules():
- if hasattr(v, 'bias') and isinstance(v.bias, nn.Parameter): # bias (no decay)
- g[2].append(v.bias)
- if isinstance(v, bn): # weight (no decay)
- g[1].append(v.weight)
- elif hasattr(v, 'weight') and isinstance(v.weight, nn.Parameter): # weight (with decay)
- g[0].append(v.weight)
+ for p_name, p in v.named_parameters(recurse=0):
+ if p_name == 'bias': # bias (no decay)
+ g[2].append(p)
+ elif p_name == 'weight' and isinstance(v, bn): # weight (no decay)
+ g[1].append(p)
+ else:
+ g[0].append(p) # weight (with decay)
if name == 'Adam':
optimizer = torch.optim.Adam(g[2], lr=lr, betas=(momentum, 0.999)) # adjust beta1 to momentum
diff --git a/yolov5s320Half.engine b/yolov5s320Half.engine
index a783c83..b42881e 100644
Binary files a/yolov5s320Half.engine and b/yolov5s320Half.engine differ